 alexxlab
alexxlab Выбор вводного автомата || ElectroHub
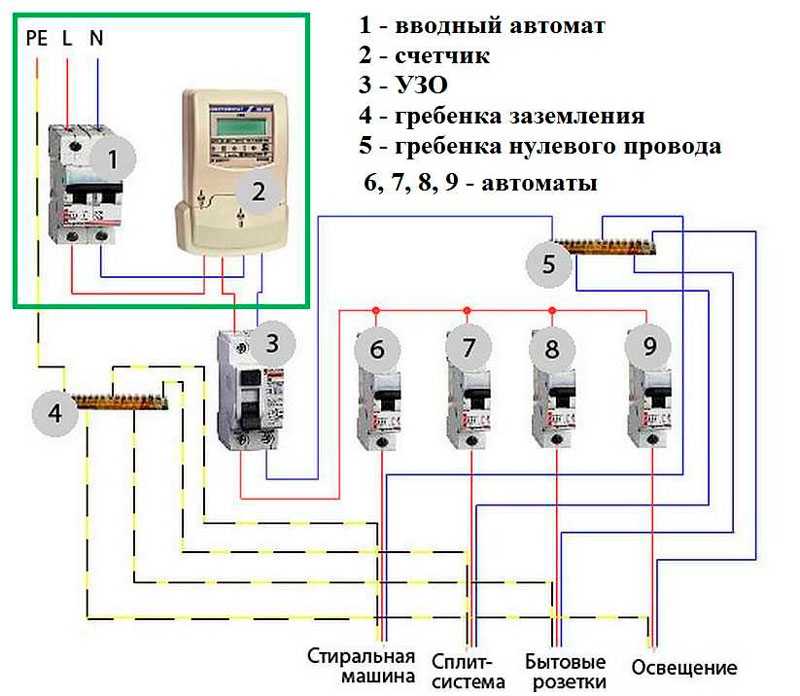
Для начала давайте рассмотрим, как организованно электроснабжение квартиры (объекта).
За исходную точку примем вводной автомат или как его многие называют до учетный автомат.
Он подключается к вводным линиям электропитания и через него производится подключение прибора учета. Основной его задачей стоит ограничение потребляемой мощности абонентом. Номинал данного автомата устанавливается энерго снабжающей организацией на основании действующих норм и правил.
Далее, после вводного автомата, устанавливается прибор учета. Оба этих устройства, как правило, находятся на балансе энерго снабжающей организации, и абонент не имеет права самостоятельно вносить изменения.
Чтобы понять, в какой части электрической сети абонент может самостоятельно вносить изменения необходимо ознакомиться с актом разграничения балансовой принадлежности электросетей. Простыми словами, этот акт подтверждает факт разделения права собственности на объектах и устанавливает ответственных лиц за их эксплуатацию.
После прибора учета в большинстве случаев наступает зона ответственности абонента и производится подключение группового распределительного щита квартиры.
Если прибор учета и вводной (ограничительный) автомат в большинстве случаев находятся вне квартиры, на лестничных площадках, то групповой распределительный щиток устанавливается непосредственно в квартире.
Первым в схеме подключения внутриквартирного щитка рекомендуется устанавливать общий групповой (после учетный) автоматический выключатель.
Если основными функциями вводного автомата являются ограничение потребляемой мощности и защита подводящего кабеля, то у общего группового автоматического выключателя задача немного другая. Он защищает от перегрузки и короткого замыкания кабель подключения между групповым щитком и прибором учета, а также его наличие в разы упрощает обслуживание группового распределительного щита
, установленного в квартире.За защиту проводки квартиры отвечают групповые автоматические выключатели, подключенные после группового (после учётного) автоматического выключателя.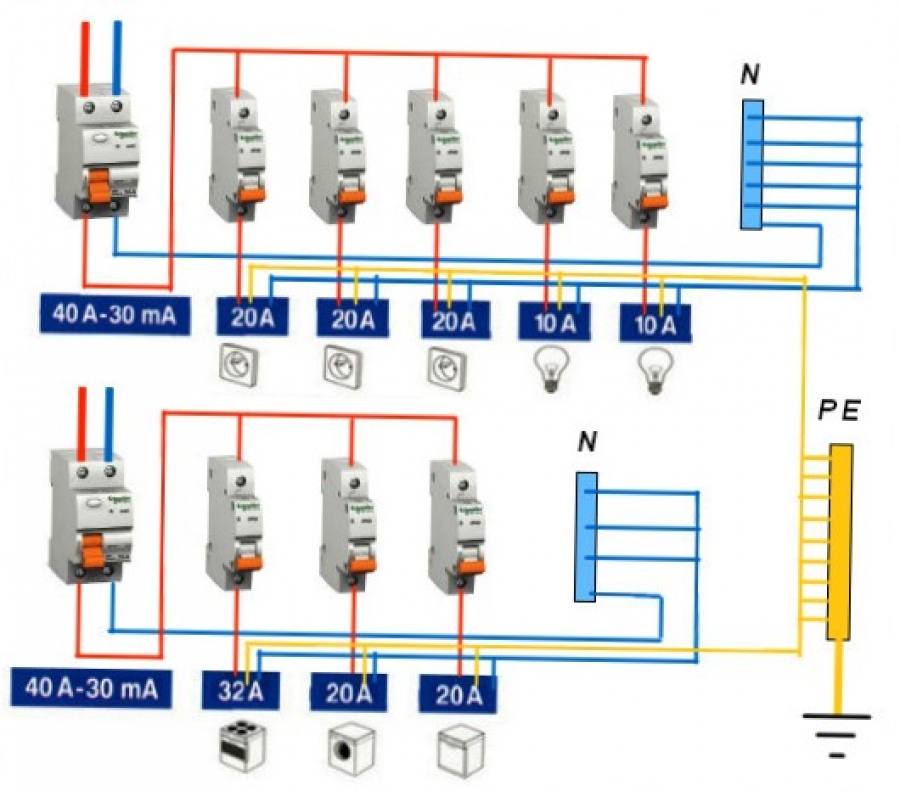
Существует ошибочное мнение, что групповые автоматические выключатели защищают подключенные электропотребители. Но это не так. Автоматический выключатель служит для защиты кабельной линии, соответственно основным параметром при выборе автомата является сечение кабеля, а не как не мощность подключаемых приборов. А вот сечение кабеля и рассчитывается по мощности присоединяемых электроприборов.
Параметры вводного, общего группового и групповых автоматических выключателей, не связаны между собой и правила расчёта номинального тока устройств защиты отличаются.
Вводной автомат — Параметры устройства определяются электрокомпанией и сечением вводного кабеля.
Общий групповой автомат – не должен иметь номинал выше вводного автомата, а также следует учитывать сечение провода соединяющего прибор учета и общий групповой автомат.
Групповые автоматы — Номинальный ток каждого из этих устройств рассчитывается на основе сечения отходящего кабеля и не должен быть меньше суммарного тока всех электроприборов группы данного устройства и служит для защиты кабельной линии данной группы.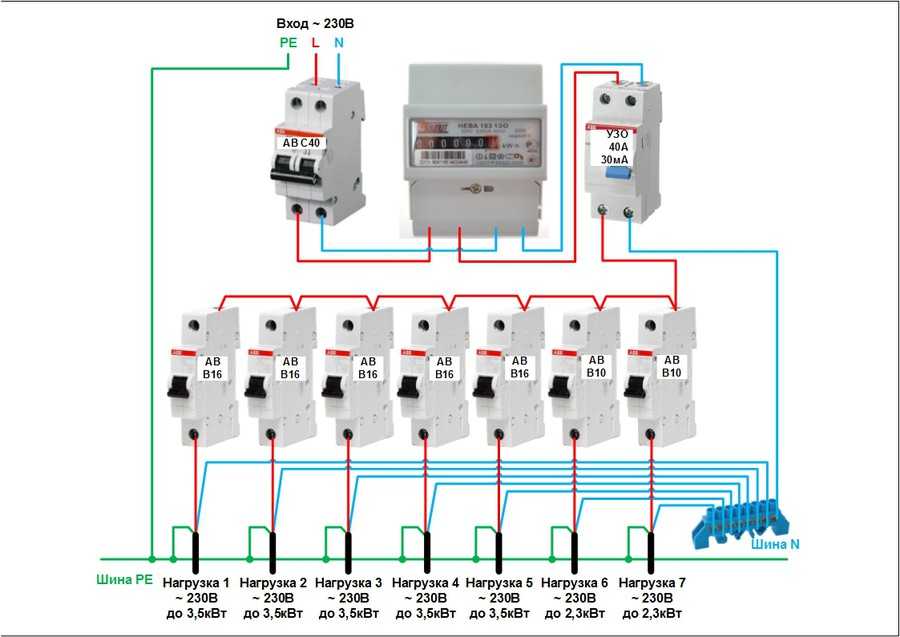
Для примера рассмотрим типовую схему квартиры, в которой установлен вводной (до учётный) автомат, ограничивающий потребление до 25 Ампер, после него подключается прибор учета и общий (после учётный) групповой автомат с номиналом в 25 Ампер.
Как видно из схемы, номинал после учётного автомата не превышает номинала до учётного автомата, а электроприборы разделены на группы автоматами со следующими номиналами:
- Бойлер 16А
- Стиральная машина 16А
- Кондиционер 16А
- Розеточная группа 16А
- Освещение 10А
- Подсветка 10А
Если произвести подсчет, то суммарный ток всех автоматических выключателей составит 84А.
При таком соотношении после учетный групповой автоматический выключатель перегружен более чем в три раза.
Как тогда получается, что схема работает и ничего не выбивает?
Такое количество групповых автоматических выключателей устанавливается для удобства эксплуатации и ремонта, а также для уменьшения сечения прокладываемых кабелей. И не стоит забывать, что номинал автомата выбирался по сечению отходящего кабеля. Если мы теперь пересчитаем непосредственную потребляемую мощность электропотребителей, то получим:
И не стоит забывать, что номинал автомата выбирался по сечению отходящего кабеля. Если мы теперь пересчитаем непосредственную потребляемую мощность электропотребителей, то получим:
- Бойлер 2000 Вт
- Стиральная машина 2000 Вт
- Кондиционер 1500 Вт
- Розеточная группа пусть у нас будет подключена нагрузка в 2000 Вт
- Освещение 5 светодиодных ламп по 12 Вт = 60 Вт
- Подсветка 10 светодиодных ламп по 5 Вт = 50 Вт
Суммарно в случае одновременного включения всех электропотребителей мы получим 7610 Вт. Что составляет ток потребления примерно в 34 Ампера.
В этой ситуации одновременное включение всей бытовой техники приведёт к отключению после учетного группового автоматического выключателя.
Чтобы этого не произошло, следует избегать одновременной работы мощных устройств. Согласитесь, навряд ли Вы сами включали одновременно все электропотребители.
Так же при расчетах берут во внимание, что одновременно подключается не более 70% всех электропотребителей.
Если Мы используем эту рекомендацию, то получим потребляемый ток в 23,8 Ампера. Соответственно вся схема будет работать в штатном режиме, и ни каких аварийных отключений происходить не будет, так как у нас что до учетный, что после учетный автоматы установлены с номиналом в 25Ампер.
Похожие статьи
Теги: Автоматический выключатель
Автомат вводной: особенности выбора вводного автомата
Содержание
- 1 Типы автоматов ввода
- 1.1 Однополюсный
- 1.2 Двухполюсный
- 1.3 Трехполюсный
- 2 Расчет автомата ввода
- 3 Выбор ВА
- 4 Установка
- 5 Видео про электрощит
При подаче электричества в квартиру на этажном электрощите могут быть установлены следующие аппараты коммутации ввода:
- автоматический выключатель;
- предохранители;
- пакетный выключатель;
- рубильник.
Вводной автомат (ВА) – это автоматический выключатель подачи электричества от питающей сети к объекту, если возникает перегрузка в цепи, или произошло короткое замыкание (КЗ).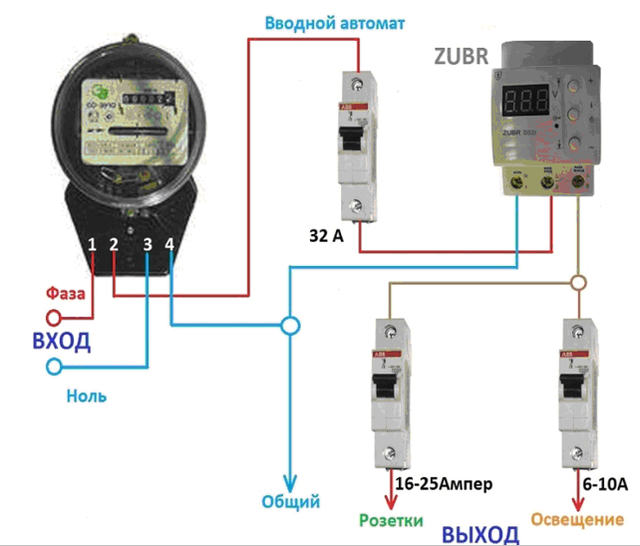 От перечисленных аппаратов он отличается большей величиной номинального тока. На фото изображен щит с расположенным в нем сверху вводным автоматом.
От перечисленных аппаратов он отличается большей величиной номинального тока. На фото изображен щит с расположенным в нем сверху вводным автоматом.
Щит с автоматическим выключателем
Правильнее называть устройство – вводный автоматический выключатель. Поскольку он ближе других устройств находится к воздушной линии, аппарат должен обладать повышенной коммутационной стойкостью (ПКС), характеризующей нормальное срабатывание устройства при возникновении КЗ (максимальный ток, при котором автоматический выключатель способен хотя бы однократно разомкнуть электрическую цепь). Показатель указывается на маркировке прибора.
Типы автоматов ввода
Подача электричества к объекту зависит от его потребностей и схемы электросети. При этом подбираются соответствующие типы автоматов.
Однополюсный
Вводный выключатель с одним полюсом применяется в электросети с одной фазой. Устройство подключается к питанию через клемму (1) сверху, а нижняя клемма (2) соединяется с отходящим проводом (рис. ниже).
ниже).
Схема однополюсного автомата
Автомат с одним полюсом устанавливается в разрыв фазного провода и отключает его от нагрузки при возникновении аварийной ситуации (рис. ниже). По принципу действия он ничем не отличается от автоматов, установленных на отводящих линиях, но его номинал по току выше (40 А).
Схема вводного однополюсного автомата
Питающая фаза красного цвета подключается к нему, а затем – к счетчику, после чего распределяется на групповые автоматы. Нейтральный провод синего цвета проходит сразу на счетчик, а с него на шину N, затем подключается к каждой линии.
Автомат ввода, установленный перед счетчиком, должен быть опломбирован.
Вводной автомат защищает кабель ввода от перегрева. Если КЗ произойдет на одной из линий ответвлений от него, сработает ее автомат, а другая линия останется работоспособной. Подобная схема подключения позволяет быстро найти и устранить неисправность во внутренней сети.
Двухполюсный
Двухполюсник представляет собой блок с двумя полюсами. Они снабжены объединенным рычажком и имеют общую блокировку между механизмами отключения. Эта конструктивная особенность важна, так как ПУЭ запрещают производить разрыв нулевого провода.
Они снабжены объединенным рычажком и имеют общую блокировку между механизмами отключения. Эта конструктивная особенность важна, так как ПУЭ запрещают производить разрыв нулевого провода.
Не допускается установка двух однополюсников вместо одного двухполюсника.
Вводной автомат с двумя полюсами применяется при однофазном вводе из-за особенностей схем подключения в домах старой постройки. В квартиру делается ответвление от стояка межэтажного электрощита однофазной двухпроводной линией. Жэковский электрик может случайно поменять местами провода, ведущие в квартиру. При этом нейтраль окажется на вводном однофазном автомате, а фаза – на нулевых шинах.
Чтобы обеспечить полную гарантию отключения, надо обесточить квартирный щиток с помощью двухполюсника. Кроме того, часто приходится менять пакетный выключатель в этажном щите. Здесь удобнее сразу поставить вместо него двухполюсный вводной автомат.
В квартиру нового дома идет сеть с фазой, нейтралью и заземлением со стандартной цветовой маркировкой. Здесь также не исключена возможность перепутывания проводов из-за низкой квалификации электрика или просто ошибки.
Здесь также не исключена возможность перепутывания проводов из-за низкой квалификации электрика или просто ошибки.
Еще одной причиной установки двухполюсника является замена пробок. На старых квартирных щитках еще остались пробки, которые установлены на фазе и на нуле. Схема соединений при этом остается прежней.
ПУЭ запрещают установку предохранителей в нулевых рабочих проводах.
Двухполюсник в данной ситуации установить удобнее, поскольку нет необходимости переделывать схему.
При подключении электричества к частному дому по схеме ТТ двухполюсник необходим, так как в такой системе возможно появления разности потенциалов между нейтральным и заземляющим проводом.
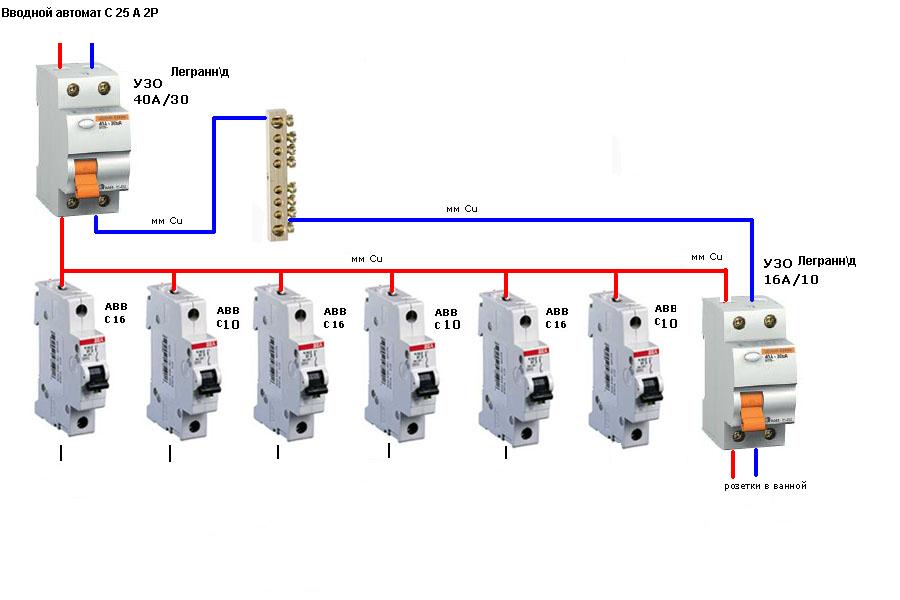
На рис. ниже изображена схема подключения электричества в квартиру с однофазным вводом через двухполюсный автомат.
Схема ввода с двухполюсным автоматом
Питающая фаза подается на него, а затем – на счетчик и на устройство противопожарного защитного заземления УЗО, после чего распределяется на групповые автоматы. Нейтральный провод проходит сразу на счетчик, с него на УЗО, шину N, а затем подключается к УЗО каждой линии. Нулевой проводник заземления зеленого цвета подключается сразу к шине PE, а с нее подходит к заземляющим контактам розеток №1 и №2.
Нейтральный провод проходит сразу на счетчик, с него на УЗО, шину N, а затем подключается к УЗО каждой линии. Нулевой проводник заземления зеленого цвета подключается сразу к шине PE, а с нее подходит к заземляющим контактам розеток №1 и №2.
Вводной автоматический выключатель защищает кабель ввода от перегрева и КЗ. Он также может сработать при КЗ на отдельной линии, если там неисправен другой автомат. Номиналы счетчика и противопожарного УЗО подбираются выше (50 А). В этом случае устройства будут также защищены вводным автоматом от перегрузок.
Трехполюсный
Устройство применяется для трехфазной сети, чтобы обеспечить одновременное отключение всех фаз при перегрузке или коротком замыкании внутренней сети.
К каждой клемме трехполюсника подключается по фазе. На рис. ниже изображены его внешний вид и схема, где для каждого контура существуют отдельные тепловой и электромагнитный расцепители, а также дугогасительная камера.
Трехполюсный автомат в шкафу и его схема
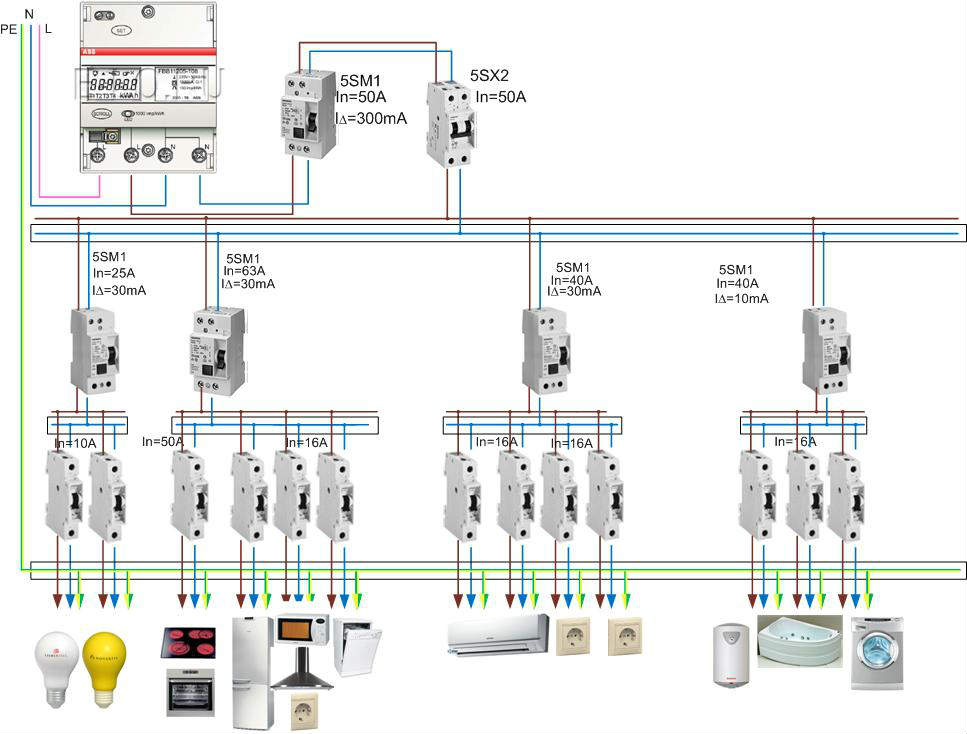
При подключении к частному дому вводной автоматический выключатель устанавливается перед электросчетчиком с защитой на 63 А (рис. ниже). После счетчика ставится УЗО на ток утечки 300 мА. Это связано с большой протяженностью электропроводки дома, где имеет место высокий фон утечки.
ниже). После счетчика ставится УЗО на ток утечки 300 мА. Это связано с большой протяженностью электропроводки дома, где имеет место высокий фон утечки.
После УЗО осуществляется разделение линий от распределительных шин (2) и (4) к розеткам, освещению, а также отдельным группам (6) подачи напряжения в пристройки, трехфазным нагрузкам и другим мощным потребителям.
Трехфазная сеть частного дома
Расчет автомата ввода
Независимо от того, является автомат вводным или нет, его рассчитывают путем суммирования токов отходящих к нагрузкам линий. Для этого определяется мощность всех подключаемых потребителей. Номинал определяется для одновременного включения всех потребителей электроэнергии. По этому максимальному току подбирается ближайший номинал автомата из стандартного ряда в сторону уменьшения.
Какой телевизионный кабель лучше: особенности выбора
Мощность вводного автомата зависит от номинального тока. При трехфазном питании мощность определяется тем, как подключены нагрузки.
Требуется также определить количество аппаратов коммутации. На ввод требуется только один выключатель, а затем по одному на каждую линию.
На мощные приборы типа электрокотла, водонагревателя, духового шкафа необходимо установить отдельные автоматы. В щитке должно быть предусмотрено место для установки дополнительных автоматических выключателей.
Выбор ВА
Выбор устройства производится по нескольким параметрам:
- Номинальный ток. Его превышение приведет к срабатыванию автомата от перегрузки. Подборка номинального тока производится по сечению подключенной проводки. Для нее определяют допустимый максимальный ток, а затем выбирают номинальный для автомата, предварительно уменьшив его на 10-15%, приводя к стандартному ряду в сторону уменьшения.
- Максимальный ток КЗ. Автомат выбирается по ПКС, которая должна быть равна ему или превышать. Если максимальный ток КЗ составляет 4500 А, подбирается автомат на 4,5 кА. Класс коммутации подбирается для освещения – В (Iпуск>Iном в 3-5 раз), для мощных нагрузок типа отопительного котла – С (Iпуск>Iном в 5-10 раз), для трехфазного двигателя большого станка или сварочного аппарата – D (Iпуск>Iном в 10-12 раз).
 Тогда защита будет надежной, без ложных срабатываний.
Тогда защита будет надежной, без ложных срабатываний. - Установленная мощность.
- Режим нейтрали – тип заземления. В большинстве случаев он представляет собой систему TN с разными вариантами (TN-C, TN-C-S, TN-S),
- Величина линейного напряжения.
- Частота тока.
- Селективность. Номиналы автоматов подбираются по распределению нагрузок в линиях, например, автомат ввода – 40 А, электроплита – 32 А, другие мощные нагрузки – 25 А, освещение – 10 А, розетки – 10 А.
- Схема питания. Автомат подбирается по количеству фаз: одно,- или двухполюсный для однофазной сети, трех,- или четырехполюсный для трехфазной.
- Изготовитель. С целью повышения степени безопасности, автомат выбирается у известных производителей и в специализированных магазинах.
Количество полюсов для трехфазной сети равно четырем. При наличии только трехфазных нагрузок со схемой подключения треугольником, можно использовать трехполюсный автомат.
Выключатель на вводе должен отключать фазы и рабочий ноль, так как в случае утечки на одной из фаз на ноль существует вероятность удара током.
Трехполюсный автомат можно применять для однофазной сети: фаза и ноль подключаются к двум клеммам, а третья останется свободной.
Выбор вводного автомата в зависимости от типа заземления:
- Система TN-S: подводящие нулевые защитный и рабочий провода разделены от подстанции до потребителя (рис. а ниже). Чтобы одновременно отключить фазы и ноль применяются двухполюсные или четырехполюсные вводные автоматы (в зависимости от количества фаз на вводе). Если они с одним или тремя полюсами, нейтраль проводится отдельно от автоматов.
- Система TN-С: подводящие нулевые защитный и рабочий провода совмещены и проходят до потребителя через общий проводник (рис. б). Автомат устанавливается однополюсный или трехполюсный на фазные проводники, а ноль вводится через счетчик на шину N.
Схемы распространенных типов заземлений
Установка
Почему выбивает автомат в щитке
Автомат ввода устанавливается в щитке сверху, с левой стороны. Отводящие линии удобно монтировать сверху вниз. При малом количестве нагрузок он может быть однополюсным и подключаться через фазный провод. В таком случае полного разрыва питающей цепи не происходит.
При малом количестве нагрузок он может быть однополюсным и подключаться через фазный провод. В таком случае полного разрыва питающей цепи не происходит.
Монтаж обычно производится на DIN-рейку, при отключении питания.
Видео про электрощит
Критерии для выбора номиналов автомата по параметрам
Ответ на вопрос, как скоммутировать вводной электрощит, можно получить из видео ниже.
Как показывает практика, подключение вводного автомата не является сложной работой. Важно правильно рассчитать его по мощности, продумать схему соединений и установить с учетом особенностей, приведенных в статье.
Пластилин Гамма «Классический», 281037, 36 цветов, 720 г
347 ₽ Подробнее
Пластилин Гамма «Классический», 281033, 12 цветов, 240 г
88 ₽ Подробнее
Кофеварки Galaxy
Оцените статью:
Нежное введение в выбор модели для машинного обучения
Джейсон Браунли on 2 декабря 2019 г. Имея простые в использовании библиотеки машинного обучения, такие как scikit-learn и Keras, можно легко подогнать множество различных моделей машинного обучения к заданному набору данных прогнозного моделирования. Таким образом, проблема прикладного машинного обучения заключается в том, как выбрать среди ряда различных моделей то, что вы можете использовать для решения своей задачи. Наивно вы можете полагать, что производительность модели достаточна, но должны ли вы учитывать другие вопросы, например, сколько времени занимает обучение модели или насколько легко ее объяснить заинтересованным сторонам проекта. Их опасения становятся более насущными, если выбранная модель должна использоваться в эксплуатации в течение месяцев или лет. Кроме того, что именно вы выбираете: только алгоритм, используемый для подбора модели, или весь конвейер подготовки данных и подгонки модели? В этом посте вы познакомитесь с проблемой выбора модели для машинного обучения. Прочитав этот пост, вы узнаете: Начнем. Нежное введение в выбор модели для машинного обучения Это руководство разделено на три части; они: Выбор модели — это процесс выбора одной окончательной модели машинного обучения из набора моделей машинного обучения-кандидатов для обучающего набора данных. Выбор модели — это процесс, который можно применять как к разным типам моделей (например, логистическая регрессия, SVM, KNN и т.

Фото Бернарда Спрагга. Новая Зеландия, некоторые права защищены. Обзор
Выбор модели
Когда у нас есть множество моделей разной сложности (например, модели линейной или логистической регрессии с полиномами разной степени или классификаторы KNN с разными значениями K), как выбрать правильную?
— стр. 22, Машинное обучение: вероятностная перспектива, 2012 г.
Например, у нас может быть набор данных, для которого мы заинтересованы в разработке модели классификации или прогнозирования регрессии. Мы не знаем заранее, какая модель лучше всего справится с этой задачей, поскольку это неизвестно. Поэтому мы подбираем и оцениваем набор различных моделей проблемы.
Выбор модели — это процесс выбора одной из моделей в качестве окончательной модели, которая решает проблему.
Выбор модели отличается от оценки модели .
Например, мы оцениваем или оцениваем модели-кандидаты, чтобы выбрать лучшую, и это выбор модели.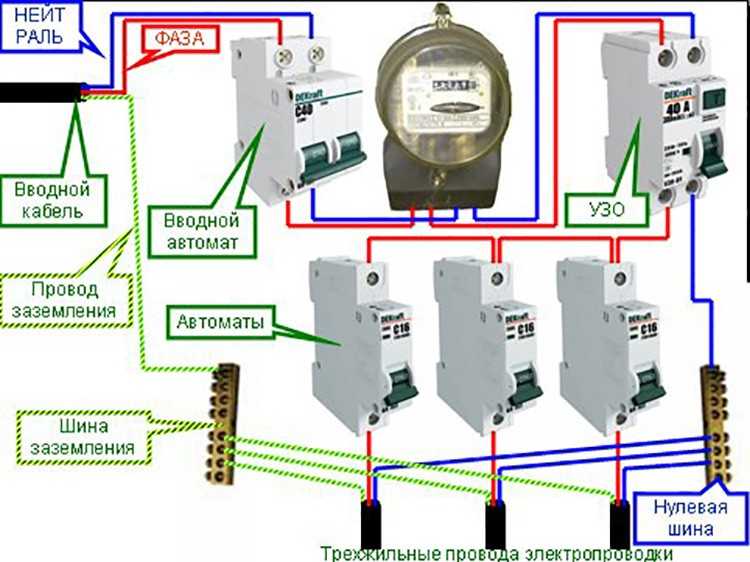
Процесс оценки производительности модели известен как оценка модели, тогда как процесс выбора надлежащего уровня гибкости для модели известен как выбор модели.
— Страница 175, Введение в статистическое обучение: с приложениями в R, 2017.
Рекомендации по выбору модели
Подгонка моделей относительно проста, хотя выбор среди них является настоящей проблемой прикладного машинного обучения.
Во-первых, нам нужно избавиться от идеи « лучшая модель ».
Все модели имеют некоторую прогностическую ошибку, учитывая статистический шум в данных, неполноту выборки данных и ограничения каждого отдельного типа модели. Следовательно, понятие идеальной или наилучшей модели бесполезно. Вместо этого мы должны искать модель, которая «
На что мы обращаем внимание при выборе конечной модели?
У участников проекта могут быть особые требования, такие как удобство сопровождения и ограниченная сложность модели. Таким образом, может быть предпочтительнее модель, которая имеет более низкий уровень навыков, но является более простой и понятной.
С другой стороны, если умение модели ценится превыше всех других соображений, то способность модели хорошо работать на данных вне выборки будет предпочтительнее независимо от сложности вычислений.
Таким образом, модель « достаточно хорошая » может относиться ко многим вещам и специфична для вашего проекта, например:
- Модель, отвечающая требованиям и ограничениям участников проекта.
- Модель, которая достаточно искусна, учитывая доступное время и ресурсы.
- Модель, более искусная по сравнению с наивными моделями.
- Модель, более умелая по сравнению с другими протестированными моделями.

- Модель, совершенная по сравнению с современным уровнем техники.
Далее мы должны рассмотреть, что выбирается.
Например, мы не выбираем подходящую модель, так как все модели будут отброшены. Это связано с тем, что как только мы выберем модель, мы подгоним новую окончательную модель ко всем доступным данным и начнем использовать ее для прогнозирования.
Следовательно, выбираем ли мы алгоритмы, используемые для подбора моделей в наборе обучающих данных?
Некоторые алгоритмы требуют специальной подготовки данных, чтобы наилучшим образом показать структуру проблемы алгоритму обучения. Поэтому мы должны сделать еще один шаг и рассмотреть выбор модели как процесс выбора среди конвейеров разработки модели.
Каждый конвейер может принимать один и тот же необработанный набор обучающих данных и выводить модель, которая может быть оценена таким же образом, но может потребовать различных или перекрывающихся вычислительных шагов, например:
- Фильтрация данных.

- Преобразование данных.
- Выбор функции.
- Разработка функций.
- И еще…
Чем внимательнее вы подходите к проблеме выбора модели, тем больше нюансов вы обнаружите.
Теперь, когда мы ознакомились с некоторыми соображениями, связанными с выбором модели, давайте рассмотрим некоторые распространенные методы выбора модели.
Методы выбора модели
Наилучший подход к выбору модели требует « достаточно » данных, которые могут быть почти бесконечными в зависимости от сложности проблемы.
В этой идеальной ситуации мы должны разделить данные на наборы для обучения, проверки и тестирования, затем подобрать модели-кандидаты в наборе для обучения, оценить и выбрать их в наборе для проверки и сообщить о производительности окончательной модели в наборе для тестирования. .
Если мы находимся в ситуации с большим количеством данных, лучший подход […] состоит в том, чтобы случайным образом разделить набор данных на три части: обучающий набор, проверочный набор и тестовый набор.
Учебный набор используется для подгонки моделей; набор проверки используется для оценки ошибки предсказания для выбора модели; набор тестов используется для оценки ошибки обобщения окончательно выбранной модели.
— стр. 222, Элементы статистического обучения: интеллектуальный анализ данных, вывод и прогнозирование, 2017 г.
Это непрактично для большинства задач прогнозного моделирования, учитывая, что у нас редко бывает достаточно данных или мы можем даже судить о том, чего будет достаточно.
Однако во многих приложениях объем данных для обучения и тестирования будет ограничен, и для построения хороших моделей мы хотим использовать для обучения как можно больше доступных данных. Однако, если набор проверки невелик, он даст относительно зашумленную оценку эффективности прогнозирования.
— стр. 32, Распознавание образов и машинное обучение, 2006.
Вместо этого существует два основных класса методов приближения к идеальному случаю выбора модели; они:
- Вероятностные показатели : Выберите модель по ошибкам в выборке и сложности.

- Методы повторной выборки : Выберите модель с помощью предполагаемой ошибки вне выборки.
Давайте рассмотрим каждый по очереди.
Вероятностные меры
Вероятностные меры включают в себя аналитическую оценку модели-кандидата с использованием как ее производительности в обучающем наборе данных, так и сложности модели.
Известно, что ошибка обучения носит оптимистический характер и поэтому не является хорошей основой для выбора модели. Производительность может быть оштрафована в зависимости от того, насколько оптимистичной считается ошибка обучения. Обычно это достигается с помощью методов, специфичных для алгоритма, часто линейных, которые снижают оценку в зависимости от сложности модели.
Исторически предлагались различные «информационные критерии», которые пытались скорректировать погрешность максимального правдоподобия путем добавления штрафного члена, чтобы компенсировать чрезмерную подгонку более сложных моделей.
— стр. 33, Распознавание образов и машинное обучение, 2006.
Модель с меньшим количеством параметров менее сложна, и поэтому она предпочтительнее, поскольку в среднем она лучше обобщает.
К четырем широко используемым вероятностным показателям выбора модели относятся:
- Информационный критерий Акаике (AIC).
- Байесовский информационный критерий (БИК).
- Минимальная длина описания (MDL).
- Минимизация структурных рисков (SRM).
Вероятностные меры подходят при использовании более простых линейных моделей, таких как линейная регрессия или логистическая регрессия, когда расчет штрафа за сложность модели (например, при смещении выборки) известен и доступен.
Методы повторной выборки
Методы повторной выборки предназначены для оценки производительности модели (или, точнее, процесса разработки модели) на данных вне выборки.
Это достигается путем разделения набора обучающих данных на наборы подпоездов и тестов, подгонки модели к набору подпоездов и оценки ее на тестовом наборе. Затем этот процесс может быть повторен несколько раз, и сообщается средняя производительность по каждому испытанию.
Затем этот процесс может быть повторен несколько раз, и сообщается средняя производительность по каждому испытанию.
Это тип оценки производительности модели методом Монте-Карло на данных вне выборки, хотя каждое испытание не является строго независимым, поскольку в зависимости от выбранного метода повторной выборки одни и те же данные могут появляться несколько раз в разных обучающих наборах данных или тестовых наборах данных. .
Три распространенных метода выбора модели передискретизации включают:
- Случайное разделение поезда/теста.
- Перекрестная проверка (k-fold, LOOCV и т. д.).
- Начальная загрузка.
В большинстве случаев вероятностные меры (описанные в предыдущем разделе) недоступны, поэтому используются методы повторной выборки.
Безусловно, наиболее популярным является семейство методов перекрестной проверки, которое включает множество подтипов.
Вероятно, самым простым и наиболее широко используемым методом оценки ошибки прогнозирования является перекрестная проверка.
— Страница 241, Элементы статистического обучения: интеллектуальный анализ данных, вывод и прогнозирование, 2017.
Примером может служить широко используемая перекрестная проверка k-fold, которая разбивает набор обучающих данных на k-кратность, где каждый пример появляется в тестовом наборе только один раз.
Другим является пропуск (LOOCV), когда тестовый набор состоит из одной выборки, и каждой выборке предоставляется возможность быть тестовой выборкой, что требует построения N (количество выборок в обучающей выборке) моделей и оценивается.
Дополнительное чтение
В этом разделе содержится больше ресурсов по теме, если вы хотите углубиться.
Учебники
- Выбор вероятностной модели с помощью AIC, BIC и MDL
- Нежное введение в статистическую выборку и повторную выборку
- Нежное введение в выборку Монте-Карло для вероятности
- Нежное введение в k-кратную перекрестную проверку
- В чем разница между тестовыми и проверочными наборами данных?
Книги
- Прикладное прогнозное моделирование, 2013.
- Элементы статистического обучения: интеллектуальный анализ данных, выводы и прогнозы, 2017 г.
- Введение в статистическое обучение: с приложениями в R, 2017 г.
- Распознавание образов и машинное обучение, 2006.
- Машинное обучение: вероятностная перспектива, 2012 г.
Артикул
- Выбор модели, Википедия.
Резюме
В этом посте вы узнали о проблеме выбора модели для машинного обучения.
В частности, вы узнали:
- Выбор модели — это процесс выбора одной из многих моделей-кандидатов для задачи прогнозного моделирования.
- При выборе модели может возникнуть множество конкурирующих проблем, помимо производительности модели, таких как сложность, ремонтопригодность и доступные ресурсы.
- Двумя основными классами методов выбора модели являются вероятностные меры и методы повторной выборки.
Есть вопросы?
Задавайте свои вопросы в комментариях ниже, и я постараюсь ответить.
О Джейсоне Браунли
Джейсон Браунли, доктор наук, специалист по машинному обучению, обучающий разработчиков тому, как получать результаты с помощью современных методов машинного обучения с помощью практических руководств.
Просмотреть все сообщения Джейсона Браунли →
Как использовать эмпирическую функцию распределения в Python
Нежное введение в байесовский оптимальный классификатор
Учебное пособие по машинному обучению с примерами
Примечание редактора. Эта статья была обновлена нашей редакцией 12.09.22. Он был изменен, чтобы включить последние источники и привести его в соответствие с нашими текущими редакционными стандартами.
Машинное обучение (ML) вступает в свои права, с растущим признанием того, что ML может играть ключевую роль в широком спектре критически важных приложений, таких как интеллектуальный анализ данных, обработка естественного языка, распознавание изображений и экспертные системы.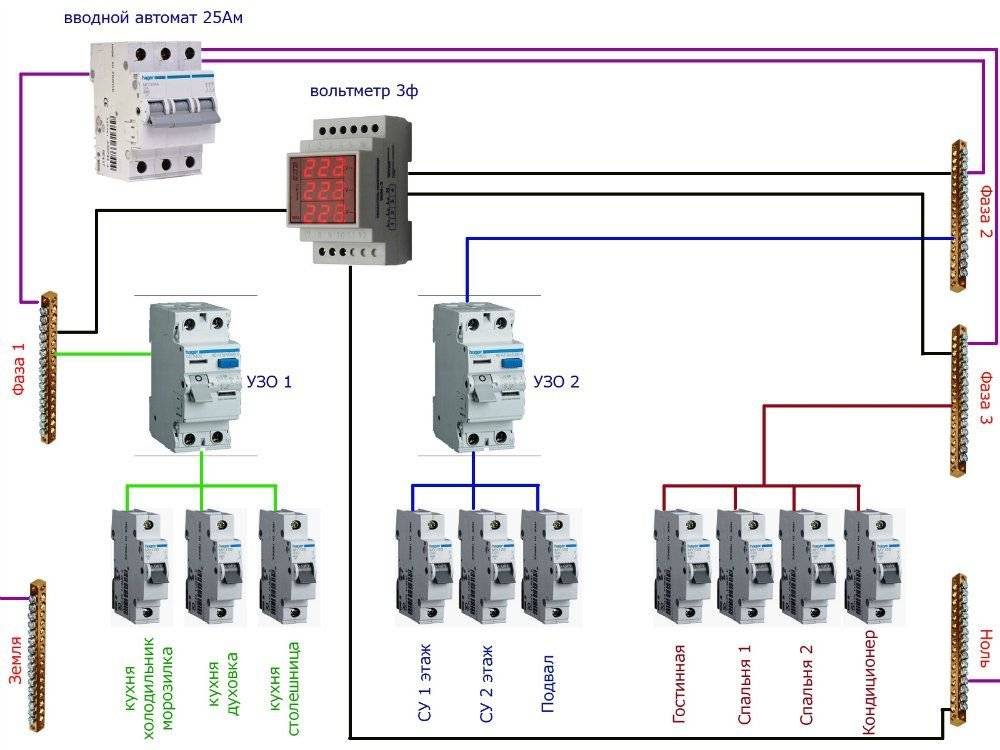 Машинное обучение предоставляет потенциальные решения во всех этих и многих других областях и, вероятно, станет опорой нашей будущей цивилизации.
Машинное обучение предоставляет потенциальные решения во всех этих и многих других областях и, вероятно, станет опорой нашей будущей цивилизации.
Предложение опытных дизайнеров машинного обучения еще не удовлетворило этот спрос. Основная причина этого заключается в том, что ML просто сложна. Это руководство по машинному обучению знакомит с базовой теорией, излагает общие темы и концепции, а также упрощает следование логике и ознакомление с основами машинного обучения.
Основы машинного обучения: что такое машинное обучение?
Так что же такое «машинное обучение»? ML это лот вещей. Область обширна и быстро расширяется, постоянно разделяясь и подразделяясь на различные подспециальности и типы машинного обучения.
Тем не менее, есть несколько основных общих черт, и всеобъемлющую тему лучше всего резюмирует это часто цитируемое заявление, сделанное Артуром Сэмюэлем еще в 1959 году: «[Машинное обучение — это] область исследования, которая дает компьютерам возможность учиться без явного программирования».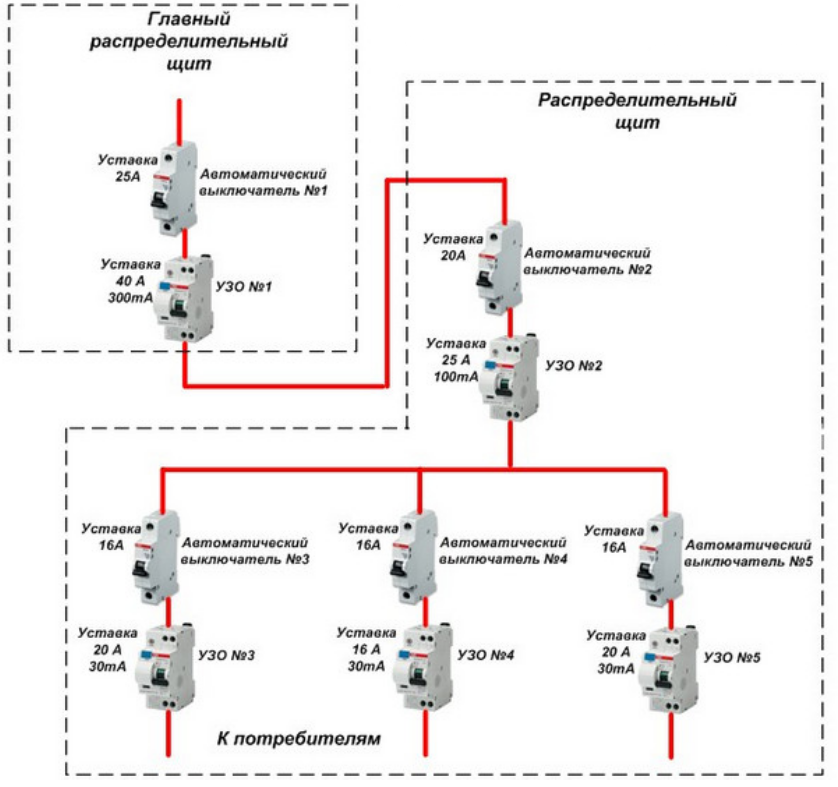
В 1997 году Том Митчелл предложил «хорошо сформулированное» определение, которое оказалось более полезным для инженеров: «Говорят, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеряемом P, улучшается с опытом E».
«Говорят, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеряемая P, улучшается с опытом E». — Том Митчелл, Университет Карнеги-Меллона.
Итак, если вы хотите, чтобы ваша программа предсказывала, например, схемы движения на оживленном перекрестке (задача T), вы можете запустить ее через алгоритм машинного обучения с данными о прошлых схемах движения (опыт E) и, если она успешно «обученный», тогда он будет лучше прогнозировать будущие модели трафика (показатель эффективности P)9.0005
Очень сложный характер многих реальных проблем, однако, часто означает, что изобретение специализированных алгоритмов, которые каждый раз будут решать их идеально, нецелесообразно, если не невозможно.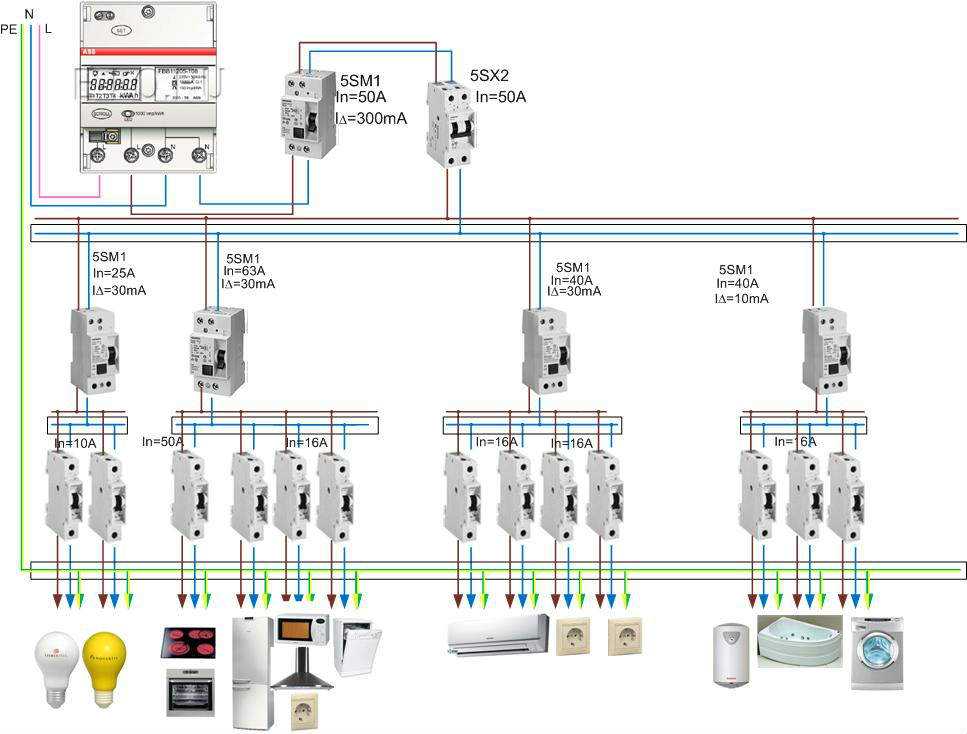
Реальные примеры проблем машинного обучения включают: «Это рак?», «Какова рыночная стоимость этого дома?», «Кто из этих людей дружит друг с другом?», «Взорвется ли этот ракетный двигатель?» при взлете?», «Понравится ли этому человеку этот фильм?», «Кто это?», «Что ты сказал?» и «Как ты управляешь этой штукой?» Все эти проблемы — отличные цели для проекта машинного обучения; на самом деле машинное обучение применялось к каждому из них с большим успехом.
ML решает задачи, которые невозможно решить только числовыми средствами.
Среди различных типов задач машинного обучения проводится важное различие между контролируемым и неконтролируемым обучением:
- Контролируемое машинное обучение — это когда программа «обучается» на предварительно определенном наборе «обучающих примеров», которые затем облегчают ее способность делать точные выводы при получении новых данных.
-
Неконтролируемое машинное обучение — это когда программе предоставляется набор данных, и она должна найти в них закономерности и отношения.
Здесь мы сосредоточимся в первую очередь на обучении с учителем, но последняя часть статьи включает краткое обсуждение обучения без учителя с некоторыми ссылками для тех, кто заинтересован в изучении этой темы.
Машинное обучение с учителем
В большинстве приложений для обучения с учителем конечной целью является разработка точно настроенной функции предсказания h(x) (иногда называемой «гипотезой»). «Обучение» состоит в использовании сложных математических алгоритмов для оптимизации этой функции таким образом, чтобы при заданных входных данных x об определенной области (скажем, площади дома) она точно предсказывала некоторое интересное значение h(x) (скажем, рыночную цену). для указанного дома).
На практике x почти всегда представляет несколько точек данных. Так, например, предиктор цен на жилье может учитывать не только квадратные метры (x1), но также количество спален (x2), количество ванных комнат (x3), количество этажей (x4), год постройки (x5), почтовый индекс ( х6) и так далее. Определение того, какие входные данные использовать, является важной частью проектирования машинного обучения. Однако для пояснения проще всего принять одно входное значение.
Определение того, какие входные данные использовать, является важной частью проектирования машинного обучения. Однако для пояснения проще всего принять одно входное значение.
Допустим, наш простой предиктор имеет следующую форму:
где и константы. Наша цель — найти идеальные значения и заставить наш предиктор работать как можно лучше.
Оптимизация предиктора h(x) выполняется с использованием обучающих примеров . Для каждого обучающего примера у нас есть входное значение x_train , для которого заранее известен соответствующий выход y . Для каждого примера мы находим разницу между известным правильным значением y и нашим предсказанным значением 9.0359 ч(x_train) . При наличии достаточного количества обучающих примеров эти различия дают нам полезный способ измерить «неправильность» h(x) . Затем мы можем настроить h(x) , изменив значения и, чтобы сделать его «менее неправильным». Этот процесс повторяется до тех пор, пока система не сойдется к лучшим значениям для и . Таким образом, предсказатель обучается и готов делать реальные предсказания.
Этот процесс повторяется до тех пор, пока система не сойдется к лучшим значениям для и . Таким образом, предсказатель обучается и готов делать реальные предсказания.
Примеры машинного обучения
Мы используем простые задачи для иллюстрации, но ML существует потому, что в реальном мире задачи намного сложнее. На этом плоском экране мы можем представить изображение не более чем трехмерного набора данных, но задачи машинного обучения часто имеют дело с данными с миллионами измерений и очень сложными предикторными функциями. ML решает проблемы, которые невозможно решить только численными средствами.
Имея это в виду, давайте рассмотрим еще один простой пример. Допустим, у нас есть следующие обучающие данные, в которых сотрудники компании оценили свою удовлетворенность по шкале от 1 до 100:
Во-первых, обратите внимание, что данные немного зашумлены. То есть, хотя мы видим, что в этом есть закономерность (т. е. удовлетворенность сотрудников имеет тенденцию расти по мере роста заработной платы), не все они четко укладываются в прямую линию.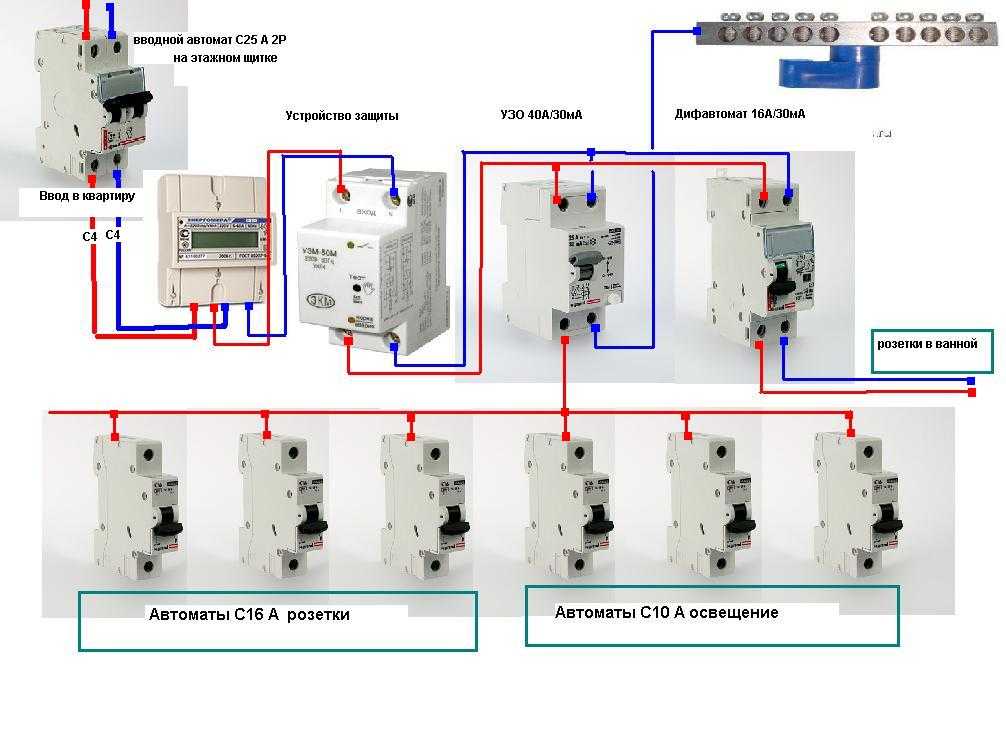 Это всегда будет иметь место с реальными данными (и мы абсолютно хотим обучить нашу машину, используя данные реального мира). Как мы можем научить машину точно предсказывать уровень удовлетворенности сотрудников? Ответ, конечно же, что мы не можем. Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Это всегда будет иметь место с реальными данными (и мы абсолютно хотим обучить нашу машину, используя данные реального мира). Как мы можем научить машину точно предсказывать уровень удовлетворенности сотрудников? Ответ, конечно же, что мы не можем. Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Чем-то напоминает знаменитое высказывание Джорджа Э. П. Бокса, британского математика и профессора статистики: «Все модели ошибочны, но некоторые из них полезны».
Цель машинного обучения никогда не состоит в том, чтобы делать «идеальные» предположения, потому что машинное обучение имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Машинное обучение в значительной степени основано на статистике. Например, когда мы обучаем нашу машину обучению, мы должны предоставить ей статистически значимую случайную выборку в качестве обучающих данных. Если обучающий набор не является случайным, мы рискуем получить шаблоны машинного обучения, которых на самом деле нет. И если обучающая выборка слишком мала (см. закон больших чисел), мы не научимся и даже можем прийти к неточным выводам. Например, попытка предсказать модели удовлетворенности в масштабах всей компании на основе данных только от высшего руководства, скорее всего, будет подвержена ошибкам.
Например, когда мы обучаем нашу машину обучению, мы должны предоставить ей статистически значимую случайную выборку в качестве обучающих данных. Если обучающий набор не является случайным, мы рискуем получить шаблоны машинного обучения, которых на самом деле нет. И если обучающая выборка слишком мала (см. закон больших чисел), мы не научимся и даже можем прийти к неточным выводам. Например, попытка предсказать модели удовлетворенности в масштабах всей компании на основе данных только от высшего руководства, скорее всего, будет подвержена ошибкам.
С этим пониманием давайте дадим нашей машине данные, которые мы дали выше, и заставим ее изучить их. Сначала мы должны инициализировать наш предиктор h(x) с некоторыми разумными значениями и . Теперь, когда мы поместим его на наш обучающий набор, наш предиктор будет выглядеть так:
Если мы спросим этот предиктор об удовлетворенности сотрудника, зарабатывающего 60 000 долларов, он предскажет рейтинг 27:
Очевидно, что это ужасная догадка и что эта машина не знает очень многого.
Теперь давайте дадим этому предсказателю все зарплаты из нашей обучающей выборки и отметим разницу между полученными прогнозируемыми рейтингами удовлетворенности и фактическими рейтингами удовлетворенности соответствующих сотрудников. Если мы проделаем небольшое математическое волшебство (которое я опишу позже в статье), мы сможем с очень высокой степенью уверенности вычислить, что значения 13,12 для и 0,61 для дадут нам лучший предиктор.
И если мы повторим этот процесс, скажем, 1500 раз, наш предсказатель будет выглядеть так:
В этот момент, если мы повторим процесс, мы обнаружим это и больше не изменимся сколько-нибудь заметно, и, таким образом, мы увидим, что система сошлась. Если мы не допустили ошибок, значит, мы нашли оптимальный предиктор. Соответственно, если теперь мы снова спросим у машины рейтинг удовлетворенности сотрудника, который зарабатывает 60 000 долларов, он предскажет оценку ~60.
Теперь мы кое к чему пришли.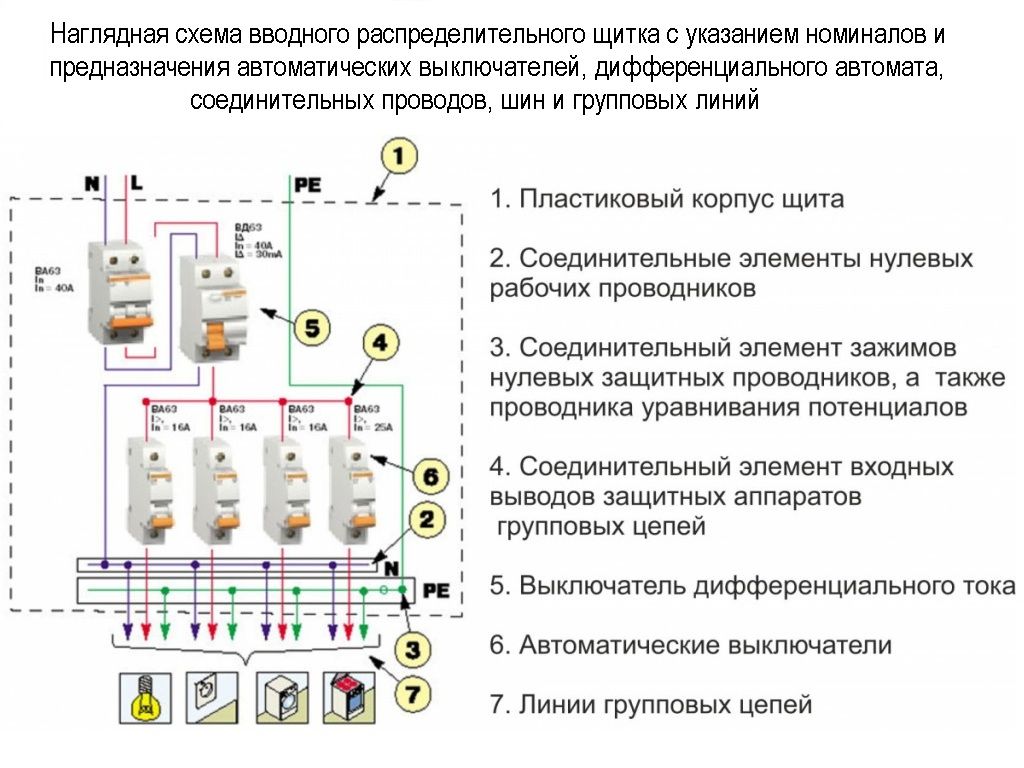
Регрессия машинного обучения: примечание о сложности
Приведенный выше пример технически представляет собой простую задачу одномерной линейной регрессии, которую в действительности можно решить, выведя простое нормальное уравнение и полностью пропустив этот процесс «настройки». Однако рассмотрим предсказатель, который выглядит следующим образом:
Эта функция принимает входные данные в четырех измерениях и имеет различные полиномиальные члены. Вывод нормального уравнения для этой функции является серьезной проблемой. Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов. Прогнозирование того, как будет выражен геном организма или каким будет климат через 50 лет, — примеры таких сложных задач.
Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов.
К счастью, итеративный подход, используемый системами машинного обучения, гораздо более устойчив к такой сложности. Вместо грубой силы система машинного обучения «чувствует» путь к ответу. Для больших задач это работает намного лучше. Хотя это не означает, что машинное обучение может решить все сколь угодно сложные проблемы — нет, — оно делает его невероятно гибким и мощным инструментом.
Градиентный спуск: минимизация «неправильности»
Давайте подробнее рассмотрим, как работает этот итеративный процесс. Как в приведенном выше примере убедиться, что с каждым шагом мы становимся лучше, а не хуже? Ответ заключается в нашем «измерении неправильности», а также в небольшом расчете. (Это «математическое волшебство», упомянутое ранее.)
Мера неправильности известна как функция стоимости (она же функция потерь ), . Входные данные представляют все коэффициенты, которые мы используем в нашем предсказателе. В нашем случае это действительно пара и .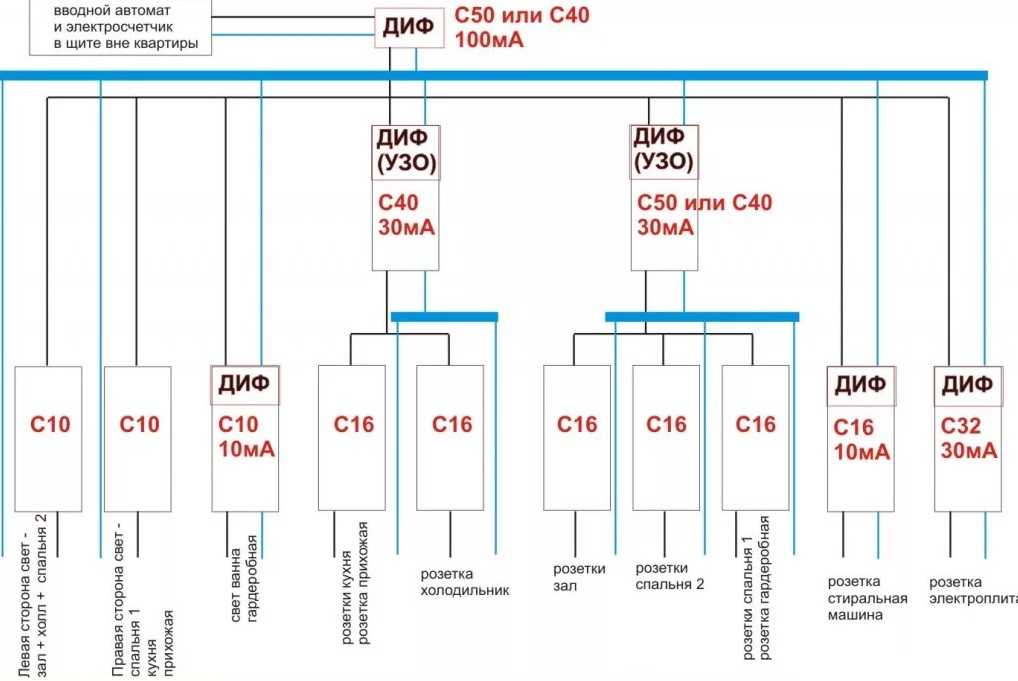 дает нам математическое измерение ошибочности нашего предиктора, когда он использует заданные значения и .
дает нам математическое измерение ошибочности нашего предиктора, когда он использует заданные значения и .
Выбор функции стоимости — еще одна важная часть программы ML. В разных контекстах быть «неправильным» может означать очень разные вещи. В нашем примере с удовлетворенностью сотрудников хорошо зарекомендовавшим себя стандартом является линейная функция наименьших квадратов:
. очень «строгое» измерение неправильности. Функция стоимости вычисляет средний штраф по всем обучающим примерам.
Теперь мы видим, что наша цель — найти и для нашего предиктора h(x) такие, чтобы наша функция стоимости была как можно меньше. Для этого мы призываем силу исчисления.
Рассмотрим следующий график функции стоимости для некоторой конкретной задачи машинного обучения:
Здесь мы можем увидеть стоимость, связанную с различными значениями и . Мы видим, что форма графика имеет небольшую чашу. Дно чаши представляет собой наименьшую стоимость, которую наш предиктор может дать нам на основе данных обучения.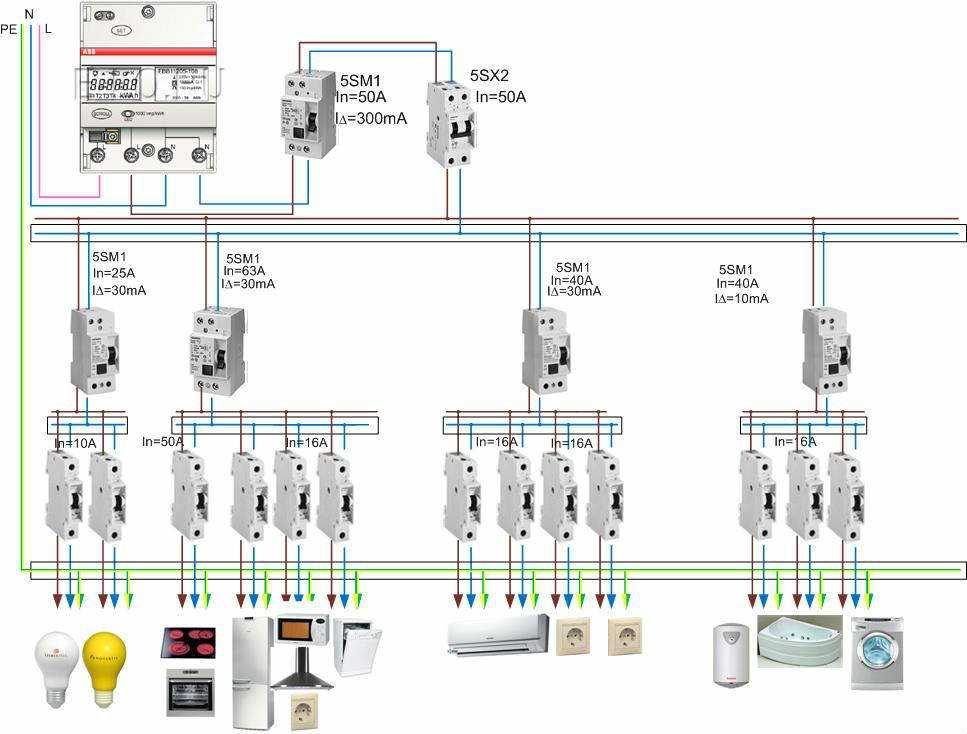 Цель состоит в том, чтобы «скатиться с горки» и найти соответствующую этой точке точку.
Цель состоит в том, чтобы «скатиться с горки» и найти соответствующую этой точке точку.
Здесь в этом учебнике по машинному обучению появляется исчисление. Чтобы не усложнять объяснение, я не буду приводить здесь уравнения, но, по сути, мы берем градиент , который является парой производных (одна над и одна над ). Градиент будет разным для каждого различного значения и и определяет «наклон холма» и, в частности, «какой путь вниз» для этих конкретных s. Например, когда мы подставляем наши текущие значения в градиент, он может сказать нам, что добавление небольшого количества к и небольшое вычитание приведет нас к дну долины функции стоимости. Поэтому прибавляем немного к , немного отнимаем от , и вуаля! Мы завершили один раунд нашего алгоритма обучения. Наш обновленный предиктор h(x) = + x будет возвращать лучшие прогнозы, чем раньше. Наша машина стала немного умнее.
Этот процесс чередования вычисления текущего градиента и обновления s по результатам известен как градиентный спуск.
Это охватывает базовую теорию, лежащую в основе большинства контролируемых систем машинного обучения. Но базовые концепции можно применять по-разному, в зависимости от решаемой проблемы.
Проблемы классификации в машинном обучении
В рамках контролируемого машинного обучения есть две основные подкатегории:
- Системы регрессионного машинного обучения — Системы, в которых прогнозируемое значение находится где-то в непрерывном спектре. Эти системы помогают нам с вопросами «Сколько?» или «Сколько?»
- Системы машинного обучения классификации — Системы, в которых мы ищем прогноз «да» или «нет», например «Является ли эта опухоль раковой?», «Соответствует ли это печенье нашим стандартам качества?» и так далее.
Как оказалось, основная теория машинного обучения более или менее одинакова. Основные отличия заключаются в конструкции предиктора h(x) и дизайн функции стоимости .
До сих пор наши примеры были сосредоточены на проблемах регрессии, поэтому теперь давайте рассмотрим пример классификации.
Вот результаты исследования качества файлов cookie, где все обучающие примеры были помечены как «хорошие файлы cookie» ( y = 1 ) синим цветом или «плохие файлы cookie» ( y = 0 ) красным цветом. .
В классификации предиктор регрессии не очень полезен. Обычно нам нужен предсказатель, который делает предположение где-то между 0 и 1. В классификаторе качества файлов cookie прогноз 1 будет представлять очень уверенное предположение о том, что печенье идеальное и очень аппетитное. Прогноз 0 означает высокую степень уверенности в том, что файл cookie является помехой для индустрии файлов cookie. Значения, попадающие в этот диапазон, представляют меньшую достоверность, поэтому мы можем спроектировать нашу систему таким образом, чтобы прогноз 0,6 означал: «Чувак, это трудный выбор, но я соглашусь с да, вы можете продать это печенье», а значение точно в середине, на уровне 0,5, может означать полную неопределенность.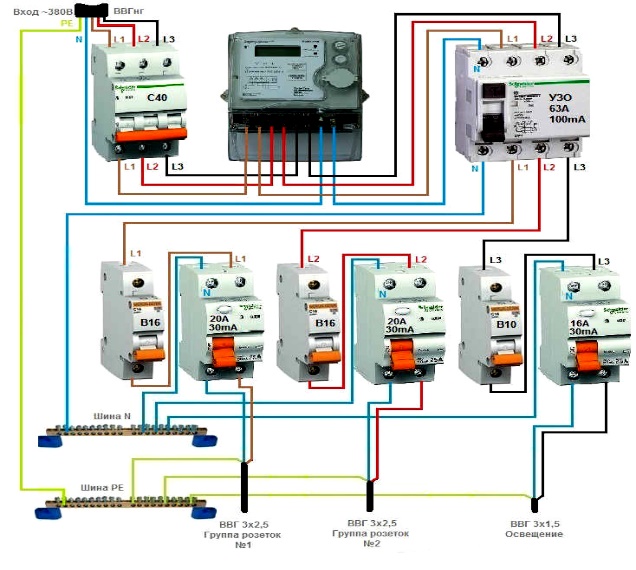 Это не всегда то, как доверие распределяется в классификаторе, но это очень распространенный дизайн, и он подходит для целей нашей иллюстрации.
Это не всегда то, как доверие распределяется в классификаторе, но это очень распространенный дизайн, и он подходит для целей нашей иллюстрации.
Оказывается, есть хорошая функция, которая хорошо фиксирует это поведение. Это называется сигмовидной функцией, g(z) , и выглядит примерно так:
z — некоторое представление наших входных данных и коэффициентов, например: :
Обратите внимание, что сигмовидная функция преобразует наши выходные данные в диапазон от 0 до 1.
Логика построения функции стоимости также различается по классификации. Мы снова спрашиваем: «Что значит, если догадка ошибочна?» и на этот раз очень хорошее эмпирическое правило заключается в том, что если правильное предположение было 0, а мы угадали 1, то мы были полностью неправы, и наоборот. Поскольку нельзя быть более неправым, чем полностью неправым, наказание в этом случае огромно. В качестве альтернативы, если правильное предположение было 0, а мы угадали 0, наша функция стоимости не должна добавлять никаких затрат каждый раз, когда это происходит. Если предположение было правильным, но мы не были полностью уверены (например,
Если предположение было правильным, но мы не были полностью уверены (например, y = 1 , но h(x) = 0,8 ), это должно стоить немного, и если наше предположение было неверным, но мы не были полностью уверены (например, y = 1 , но h( x) = 0,3 ), это должно быть сопряжено со значительными затратами, но не такими большими, как если бы мы были полностью неправы.
Это поведение фиксируется функцией журнала, так что:
Опять же, функция стоимости дает нам среднюю стоимость по всем нашим обучающим примерам.
Итак, здесь мы описали, как предиктор h(x) и функция стоимости различаются между регрессией и классификацией, но градиентный спуск по-прежнему работает нормально.
Предиктор классификации можно визуализировать, нарисовав граничную линию; т. е. барьер, при котором прогноз изменяется с «да» (прогноз больше 0,5) на «нет» (прогноз меньше 0,5). С хорошо спроектированной системой наши данные о файлах cookie могут генерировать границу классификации, которая выглядит следующим образом:
Вот это машина, которая кое-что знает о файлах cookie!
Введение в нейронные сети
Обсуждение машинного обучения было бы неполным без упоминания хотя бы нейронных сетей. Нейронные сети не только предлагают чрезвычайно мощный инструмент для решения очень сложных проблем, они также предлагают увлекательные подсказки о работе нашего собственного мозга и интригующие возможности для создания действительно интеллектуальных машин за один день.
Нейронные сети не только предлагают чрезвычайно мощный инструмент для решения очень сложных проблем, они также предлагают увлекательные подсказки о работе нашего собственного мозга и интригующие возможности для создания действительно интеллектуальных машин за один день.
Нейронные сети хорошо подходят для моделей машинного обучения, где количество входных данных огромно. Вычислительные затраты на решение такой задачи слишком велики для типов систем, которые мы обсуждали. Однако оказывается, что нейронные сети можно эффективно настраивать с помощью методов, которые в принципе поразительно похожи на градиентный спуск.
Подробное обсуждение нейронных сетей выходит за рамки этого руководства, но я рекомендую ознакомиться с предыдущим постом на эту тему.
Неконтролируемое машинное обучение
Неконтролируемое машинное обучение обычно направлено на поиск взаимосвязей в данных. В этом процессе не используются обучающие примеры. Вместо этого системе дается набор данных и ставится задача найти в них закономерности и корреляции. Хороший пример — выявление сплоченных групп друзей в данных социальных сетей.
Хороший пример — выявление сплоченных групп друзей в данных социальных сетей.
Алгоритмы машинного обучения, используемые для этого, очень отличаются от тех, которые используются для обучения с учителем, и эта тема заслуживает отдельного сообщения. Однако, чтобы тем временем поразмыслить, взгляните на алгоритмы кластеризации, такие как k-средние, а также изучите системы уменьшения размерности, такие как анализ основных компонентов. Вы также можете прочитать нашу статью о полуконтролируемой классификации изображений.
Применение теории на практике
Мы рассмотрели большую часть базовой теории, лежащей в основе области машинного обучения, но, конечно, мы коснулись только самой поверхности.
Имейте в виду, что для реального применения теорий, содержащихся в этом введении, к реальным примерам машинного обучения необходимо гораздо более глубокое понимание этих тем. В машинном обучении есть много тонкостей и ловушек, а также множество способов сбиться с пути того, что кажется отлично настроенной мыслящей машиной. Почти с каждой частью базовой теории можно играть и изменять бесконечно, и результаты часто бывают ошеломляющими. Многие вырастают в совершенно новые области исследований, которые лучше подходят для решения конкретных проблем.
Почти с каждой частью базовой теории можно играть и изменять бесконечно, и результаты часто бывают ошеломляющими. Многие вырастают в совершенно новые области исследований, которые лучше подходят для решения конкретных проблем.
Очевидно, что машинное обучение — невероятно мощный инструмент. В ближайшие годы он обещает помочь решить некоторые из наших самых насущных проблем, а также открыть совершенно новые возможности для фирм, занимающихся наукой о данных. Спрос на инженеров по машинному обучению будет только расти, предлагая невероятные шансы стать частью чего-то большого. Надеюсь, вы подумаете о том, чтобы принять участие в акции!
Благодарность
Эта статья основана на материалах, преподаваемых профессором Стэнфордского университета доктором Эндрю Нг в его бесплатном и открытом курсе «Машинное обучение с учителем». Он подробно описывает все, что обсуждается в этой статье, и дает множество практических советов специалистам по машинному обучению. Я не могу рекомендовать его достаточно высоко для тех, кто заинтересован в дальнейшем изучении этой увлекательной области.