 alexxlab
alexxlab Что такое CI (Continuous Integration) / Хабр
CI (Continuous Integration) — в дословном переводе «непрерывная интеграция». Имеется в виду интеграция отдельных кусочков кода приложения между собой. Чем чаще мы собираем код воедино и проверяем:
- Собирается ли он?
- Проходят ли автотесты?
Тем лучше! CI позволяет делать такие проверки автоматически. Он используется в продвинутых командах разработки, которые пишут не только код, но и автотесты. Его спрашивают на собеседованиях — хотя бы понимание того, что это такое. Да, даже у тестировщиков.
Поэтому я расскажу в статье о том, что это такое. Как CI устроен и чем он пригодится вашему проекту. Если вы больше любите видео-формат, можно посмотреть мой ролик на youtube на ту же тему.
Содержание
- Что такое CI
- Программы CI
- Как это выглядит
- Как CI устроен
- Интеграция с VCS
- CI в тестировании
- Итого
Что такое CI
CI — это сборка, деплой и тестирование приложения без участия человека. Сейчас объясню на примере.
Сейчас объясню на примере.
Допустим, что у нас есть два разработчика — Маша и Ваня. И тестировщица Катя.
Маша пишет код. Добавляет его в систему контроля версий (от англ. Version Control System, VCS). Это что-то типа дропбокса для кода — место хранения, где сохраняются все изменения и в любой момент можно посмотреть кто, что и когда изменял.
Потом Ваня заканчивает свой кусок функционала. И тоже сохраняет код в VCS.
Но это просто исходный код — набор файликов с расширением .java, или любым другим. Чтобы Катя могла протестировать изменения, нужно:
- Собрать билд из исходного кода
- Запустить его на тестовой машине
Сборка билда — это когда мы из набора файликов исходного кода создаем один запускаемый файл:
Собрать билд можно вручную, но это лишний геморрой: нужно помнить, что в каком порядке запустить, какие файлики зависят друг от друга, не ошибиться в команде… Обычно используют специальную программу. Для java это Ant, Maven или Gradle. С помощью сборщика вы один раз настраиваете процесс сборки, а потом запускаете одной командой. Пример запуска для Maven:
Для java это Ant, Maven или Gradle. С помощью сборщика вы один раз настраиваете процесс сборки, а потом запускаете одной командой. Пример запуска для Maven:
mvn clean install
Это полуавтоматизация — все равно нужен человек, который введет команду и соберет билд «ручками». Допустим, этим занимаются разработчики. Когда Катя просит билд на тестирование, Ваня обновляет версию из репозитория и собирает билд.
Но собрать билд ≠ получить приложение для тестирования. Его еще надо запустить! Этим занимается сервер приложения. Серверы бывают разные: wildfly, apache, jetty…
Если это wildfly, то нужно:
- Подложить билд в директорию standalone/deployments
- Запустить сервер (предварительно один раз настроив службу)
И это снова полуавтоматизация. Потому что разработчику нужно скопировать получившийся после сборки архив на тестовый стенд и включить службу. Да, это делается парой команд, но все равно человеком.
Да, это делается парой команд, но все равно человеком.
А вот если убрать из этой схемы человека — мы получим CI!
CI — это приложение, которое позволяет автоматизировать весь процесс. Оно забирает изменения из репозитория с кодом. Само! Тут есть два варианта настройки:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.
- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)
Когда CI получило изменения, оно запускает сборку билда и автотесты.
Если сборка провалилась (тесты упали, или не получилось собрать проект), система пишет электронное письмо всем заинтересованным лицам:
- Менеджеру проекта (чтобы знал, что делается!)
- Разработчику, который внес изменения
- Любому другому — как настроите, так и будет.
Если сборка прошла успешно, CI разворачивает приложение на тестовой машине. И в итоге Катька может тестировать новую сборку!
И в итоге Катька может тестировать новую сборку!
Да, разумеется, один раз придется это все настроить — рассказать серверу CI, откуда забирать изменения, какие автотесты запускать, как собирать проект, куда его потом билдить… Но зато один раз настроил — а дальше оно само!
Автотесты тоже придется писать самим, но чтож поделать =)
Если на пальцах, то система CI (Continuous Integration) – это некая программа, которая следит за вашим Source Control, и при появлении там изменений автоматически стягивает их, билдит, гоняет автотесты (конечно, если их пишут).В случае неудачи она дает об этом знать всем заинтересованным лицам, в первую очередь – последнему коммитеру. (с) habr.com/ru/post/352282
Программы CI
Наиболее популярные — Jenkins и TeamCity.
Но есть куча других вариаций — CruiseControl, CruiseControl.Net, Atlassian Bamboo, Hudson, Microsoft Team Foundation Server.
Как это выглядит
Давайте посмотрим, как это выглядит с точки зрения пользователя.
Когда я захожу в систему, я вижу все задачи. Задачи бывают разные:
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
Задачи можно группировать. Вот, скажем, у нас есть проект CDI. Зайдя внутрь, я вижу задачи именно по этому проекту:
- CDI Archetype и CDI Core — это билды. Они проверяют, что приложение вообще собирается. Отрабатывают за пару минут и прогоняются на каждое изменение кода.
- CDI Core with tests — сборка проекта со всеми автотестами, которых, как видно на скрине, 4000+ штук. Тесты идут полчаса, но тоже прогоняются на каждый коммит.
Помимо автоматизированного запуска, я могу в любой момент пересобрать билд, нажав на кнопку «Run»:
Это нужно, чтобы:
- Перезапустить тесты, исправив косяк — это ведь может быть настройки окружения, а не кода.
 Поэтому исправление настройки не перезапустит тесты, которые следят только за системой контроля версий кода.
Поэтому исправление настройки не перезапустит тесты, которые следят только за системой контроля версий кода. - Перезапустить билд, если TeamCIty настроен проверять изменения раз в час — а нам нужно сейчас проверить исправления
- Перезапустить билд, если в VCS исправления вносились не в этот проект, а в связанный.
- Проверить стабильность падения — иногда тесты падают по неведомым причинам, а если их перезапустить, отработают успешно.
Когда я захожу внутрь любой задачи — я вижу историю сборок. Когда она запускалась? Кто при этом вносил изменения и сколько их было? Сколько тестов прошло успешно, а сколько развалилось?
Поэтому, даже если я не подписана на оповещения на электронную почту о состоянии сборок, я легко могу посмотреть, в каком состоянии сейчас система. Открываешь графический интерфейс программы и смотришь.
Как CI устроен
Как и где CI собирает билд и прогоняет автотесты? Я расскажу на примере TeamCity, но другие системы работают примерно также.
Сам TeamCity ничего не собирает. Сборка и прогон автотестов проходят на других машинах, которые называются «агенты»:
«Агент» — это простой компьютер. Железка или виртуальная машина, не суть. Но как этот комьютер понимает, что ему надо сделать?
В TeamCity есть сервер и клиент. Сервер — это то самое приложение, в котором вы потом будете тыкать кнопочки и смотреть красивую картинку «насколько все прошло успешно». Он устанавливается на одну машину.
А приложение-«клиент» устанавливается на машинах-«агентах». И когда мы нажимаем кнопку «Run» на сервере:
Сервер выбирает свободного клиента и передает ему все инструкции: что именно надо сделать. Клиент собирает билд, выполняет автотесты, собирает результат и возвращает серверу: «На, держи, отрисовывай».
Сервер отображает пользователю результат плюс рассылает email всем заинтересованным лицам.
При этом мы всегда видим, на каком конкретно агенте проходила сборка:
И можно самому выбирать, где прогонять автотесты. Потому что бывает, что автотесты падают только на одном билд-агенте. Это значит, что у него что-то не так с конфигурацией.
Потому что бывает, что автотесты падают только на одном билд-агенте. Это значит, что у него что-то не так с конфигурацией.
Допустим, исходно у нас был только один билд-агент — Buran. Название может быть абсолютно любым, его придумывает администратор, когда подключает новую машину к TeamCity как билд-агента. Мы собирали на нем проект, проводили автотесты — все работало. А потом закупили вторую машинку и назвали Apollo. Вроде настроили также, как Буран, даже операционную систему одинаковую поставили — CentOs 7.Но запускаем сборку на Apollo — падает. Причем падает странно, не хватает памяти или еще чего-то. Перезапускаем на Apollo — снова падает. Запускаем на Буране — проходит успешно!
Начинаем разбираться и выясняем, что в Apollo забыли про какую-то настройку. Например, не увеличили количество открытых файловых дескриптеров. Исправили, прогнали сборку на Apollo — да, работает, ура!
Мы также можем для каждой сборки настроить список агентов, на которых она может выполняться. Зачем? Например, у нас на половине агентов линукс, а на половине винда. А сборку мы только под одну систему сделали. Или на винде вылезает какой-то плавающий баг, но исправлять его долго и дорого, а все клиенты на линуксе — ну и зачем тогда?
Зачем? Например, у нас на половине агентов линукс, а на половине винда. А сборку мы только под одну систему сделали. Или на винде вылезает какой-то плавающий баг, но исправлять его долго и дорого, а все клиенты на линуксе — ну и зачем тогда?
А еще бывает, что агентов делят между проектами, чтобы не было драки — этот проект использует Бурана и Аполло, а тот Чип и Дейла. Фишка ведь в том, что на одном агенте может выполняться только одно задание. Поэтому нет смысла покупать под агент крутую тачку, сразу кучу тестов там все равно не прогнать.
В итоге как это работает: сначала админ закупает компьютеры под «агенты» и устанавливает на них клиентское приложение TeamCity. Слишком крутыми они быть не должны, потому что много задач сразу делать не будут.
При этом TeamCity вы платите за количество лицензий на билд-агентов. Так что чем меньше их будет, тем лучше.
На отдельной машине админ устанавливает сервер TeamCity. И конфигурирует его — настраивает сборки, указывает, какие сборки на каких машинах можно гонять, итд.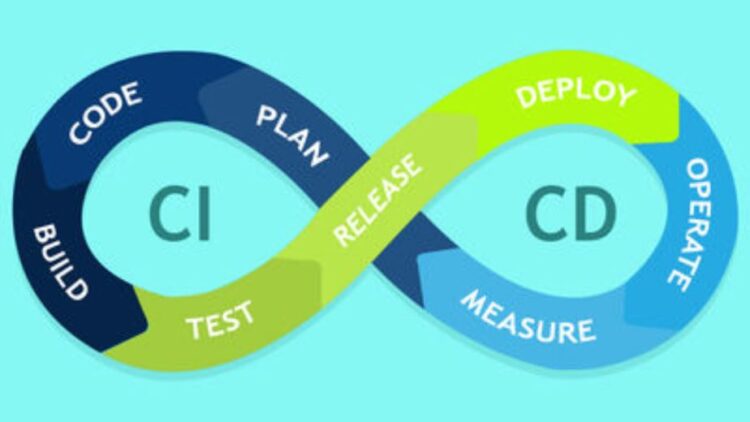 На сервере нужно место для хранения артефактов — результатов выполнения сборки.
На сервере нужно место для хранения артефактов — результатов выполнения сборки.
У нас есть два проекта — Единый клиент и Фактор, которые взаимодействуют между собой. Тестировщик Единого клиента может не собирать Фактор локально. Он запускает сборку в TeamCity и скачивает готовый билд из артефактов!
Дальше уже разработчик выбирает, какую сборку он хочет запустить и нажимает «Run». Что в этот момент происходит:
1. Сервер TeamCity проверяет по списку, на каких агентах эту сборку можно запускать. Потом он проверяет, кто из этих агентов в данный момент свободен:
Нашел свободного? Отдал ему задачку!
Если все агенты заняты, задача попадает в очередь. Очередь работает по принципу FIFO — first in, first out. Кто первый встал — того и тапки.
Очередь можно корректировать вручную. Так, если я вижу, что очередь забита сборками, которые запустила система контроля версий, я подниму свою на самый верх.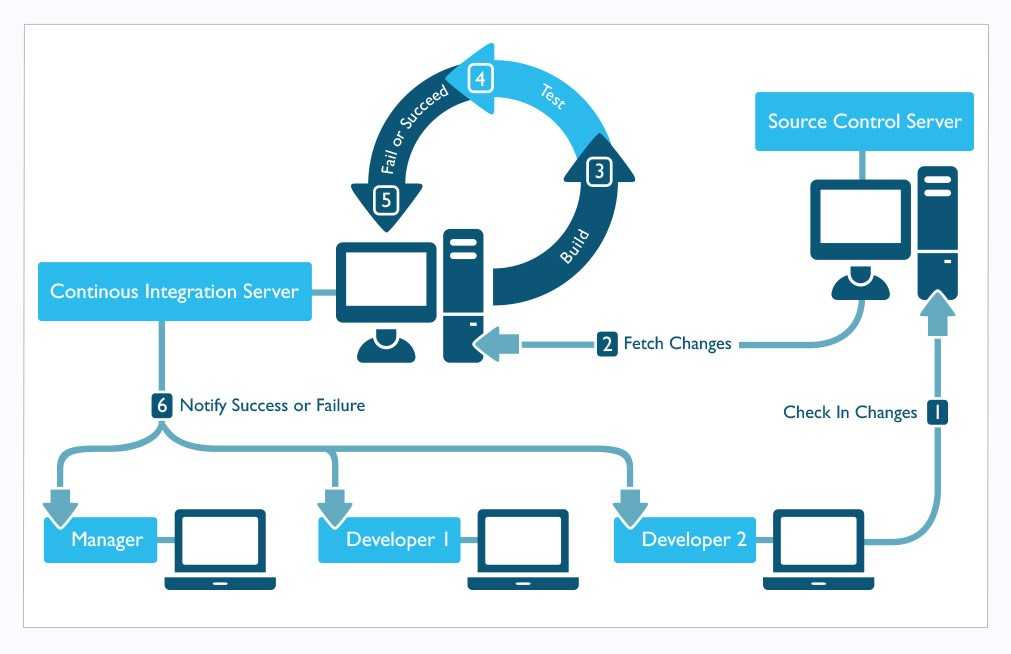 Если я вижу, что сборки запускали люди — значит, они тоже важные, придется подождать.
Если я вижу, что сборки запускали люди — значит, они тоже важные, придется подождать.
Это нормальная практика, если мощностей агентов не хватает на всей и создается очередь. Смотришь, кто ее запустил:
- Робот? Значит, это просто плановая проверка, что ничего лишнего не разломалось. Такая может и подождать 5-10-30 минут, ничего страшного
- Коллега? Ему эта сборка важна, раз не стал ждать планового запуска. Встаем в очередь, лезть вперед не стоит.
Иногда можно даже отменить сборку от системы контроля версий, если уж очень припекло, а все агенты занятами часовыми тестами. В таком случае можно:
- поднять свою очередь на самый верх, чтобы она запустилась на первом же освободившемся агенте
- зайти на агент, отменить текущую сборку
- перезапустить ее! Хоть она и попадет в самый низ очереди, но просто отменять сборку некрасиво
2. Агент выполняет задачу и возвращает серверу результат
Агент выполняет задачу и возвращает серверу результат
3. Сервер отрисовывает результат в графическом интерфейсе и сохраняет артефакты. Так я могу зайти в TeamCity и посмотреть в артефактах полные логи прошедших автотестов, или скачать сборку проекта, чтобы развернуть ее локально.
Настоятельно рекомендуется настроить заранее количество сборок, которые CI будет хранить. Потому что если в артефактах лежат билды по 200+ мб и их будет много, то очередной запуск сборки упадет с ошибкой «кончилось место на диске»:
4. Сервер делает рассылку по email — тут уж как настроите. Он может и позитивную рассылку делать «сборка собралась успешно», а может присылать почту только в случае неудачи «Ой-ей-ей, что-то пошло не так!».
Интеграция с VCS
Я говорила о разных вариантах настройки интеграции CI — VCS:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.
- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)
Но когда какой используется?
Лучше всего, конечно, чтобы система контроля версий оповещала сервер CI.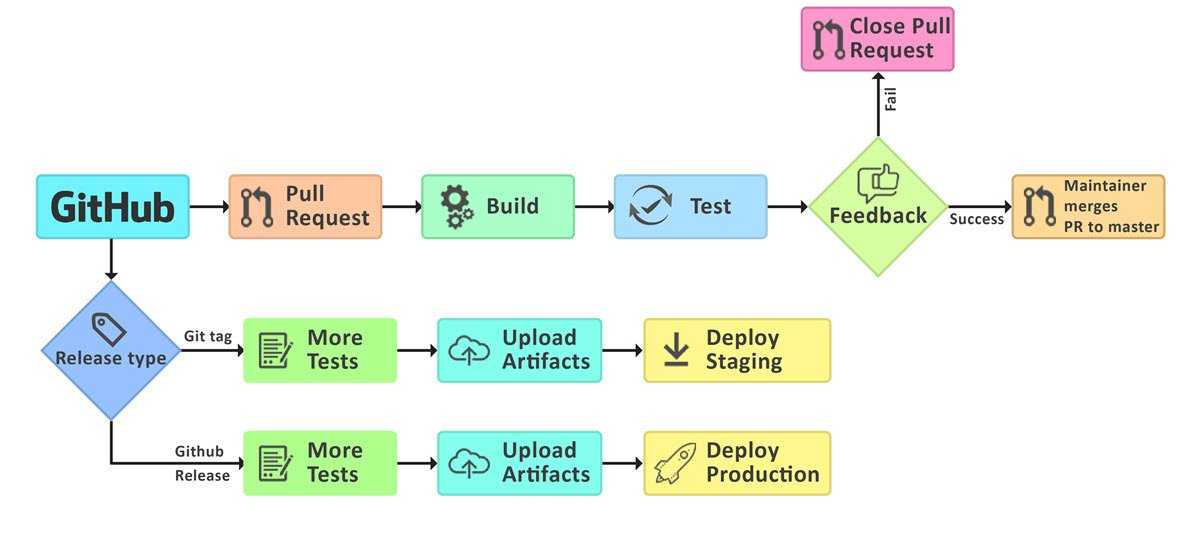 И запускать весь цикл на каждое изменение: собрать, протестировать, задеплоить. Тогда любое изменение кода сразу попадет на тестовое окружение, которое будет максимально актуальным.
И запускать весь цикл на каждое изменение: собрать, протестировать, задеплоить. Тогда любое изменение кода сразу попадет на тестовое окружение, которое будет максимально актуальным.
Плюс каждое изменение прогоняет автотесты. И если тесты упадут, сразу ясно, чей коммит их сломал. Ведь раньше работало и после Васиных правок вдруг сломалось — значит, это его коммит привел к падению. За редким исключением, когда падение плавающее.
Но в реальной жизни такая схема редко применима. Только подумайте — у вас ведь может быть много проектов, много разработчиков. Каждый что-то коммитит ну хотя бы раз в полчаса. И если на каждый коммит запускать 10 сборок по полчаса — очереди в TeamCity никогда не разгребутся!
У нас у одного из продуктов есть core-модуль, а есть 15+ Заказчиков. В каждом свои автотесты. Сборка заказчика — это core + особенности заказчика. То есть изменение в корневом проекте может повлиять на 15 разных сборок. Значит, их все надо запустить при коммите в core.
Когда у нас было 4 билд-агента, все-все-все сборки и тесты по этим заказчикам запускались в ночь на вторник. И к 10 утра в TeamCity еще была очередь на пару часов.
Другой вариант — закупить много агентов. Но это цена за саму машину + за лицензию в TeamCity, что уже сильно дороже, да еще и каждый месяц платить.
Поэтому обычно делают как:
1. Очень быстрые и важные сборки можно оставить на любой коммит — если это займет 1-2 минуты, пусть гоняется.
2. Остальные сборки проверяют, были ли изменения в VCS — например, раз в 15 минут. Если были, тогда запускаем.
3. Долгие тесты (например, тесты производительности) — раз в несколько дней ночью.
CI в тестировании
Если мы говорим о разработке своего приложения, то тестирование входит в стандартный цикл. Вы или ваши разработчики пишут автотесты, которые потом гоняет CI. Это могут быть unit, api, gui или нагрузочные тесты.
Но что, если вы тестируете черный ящик? Приложение есть, исходного кода нету. Это суровые реалии тестировщиков интеграции — поставщик отдает вам новый релиз приложения, который нужно проверить перед тем, как ставить в продакшен.
Вот, допустим, у вас есть API-тесты в Postman-е. Или GUI-тесты в Selenium. Можно ли настроить цикл CI для них?
Конечно, можно!
CI не ставит жестких рамок типа «я работаю только в проектах с автотестами» или «я работаю только когда есть доступ к исходному коду». Он может смотреть в систему контроля версий, а может и не смотреть. Это необязательное условие!
Написали автотесты? Скажите серверу CI, как часто их запускать — и наслаждайтесь результатом =)
Итого
CI — непрерывная интеграция. Это когда ваше приложение постоянно проверяется: все ли с ним хорошо? Проходят ли тесты? Собирается ли сборка? Причем все проверки проводятся автоматически, без участия человека.
Особенно актуально для команд, где над кодом одного приложения трудятся несколько разработчиков. Как это бывает? По отдельности части программы работают, а вот вместе уже нет. CI позволяет очень быстро обнаружить такие проблемы. А чем быстрее найдешь — тем дешевле исправить.
Отсюда и название — постоянная проверка интеграции кусочков кода между собой.
Типичные задачи CI:
- Проверить, было ли обновление в коде
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
И все это — автоматически, без вмешательства человека! То есть один раз настроили, а дальше оно само.
Если в проекте настроен CI, у вас будут постоянно актуальные тестовые стенды. И если в коде что-то сломается, вы узнаете об этом сразу, сервер CI пришлет письмо.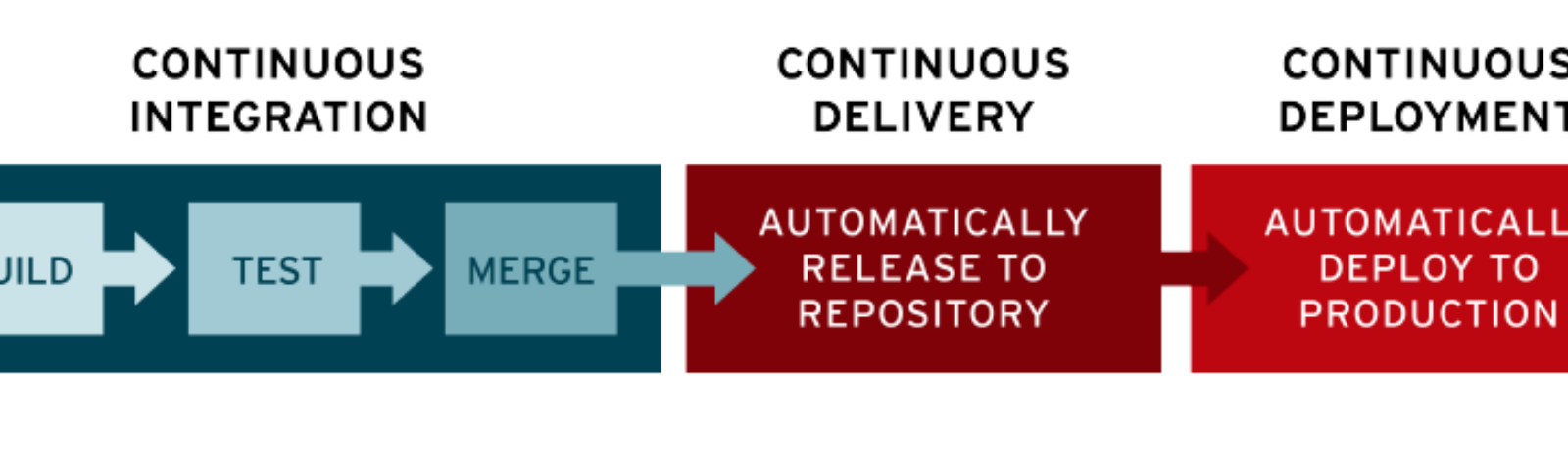 А еще можно зайти в графический интерфейс и посмотреть — все ли сборки успешные, а тесты зеленые? Оценить картину по проекту за минуту.
А еще можно зайти в графический интерфейс и посмотреть — все ли сборки успешные, а тесты зеленые? Оценить картину по проекту за минуту.
См также:
Continuous Integration для новичков
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Что такое CI (Continuous Integration) / Хабр
CI (Continuous Integration) — в дословном переводе «непрерывная интеграция». Имеется в виду интеграция отдельных кусочков кода приложения между собой. Чем чаще мы собираем код воедино и проверяем:
- Собирается ли он?
- Проходят ли автотесты?
Тем лучше! CI позволяет делать такие проверки автоматически. Он используется в продвинутых командах разработки, которые пишут не только код, но и автотесты. Его спрашивают на собеседованиях — хотя бы понимание того, что это такое. Да, даже у тестировщиков.
Поэтому я расскажу в статье о том, что это такое. Как CI устроен и чем он пригодится вашему проекту. Если вы больше любите видео-формат, можно посмотреть мой ролик на youtube на ту же тему.
Как CI устроен и чем он пригодится вашему проекту. Если вы больше любите видео-формат, можно посмотреть мой ролик на youtube на ту же тему.
Содержание
- Что такое CI
- Программы CI
- Как это выглядит
- Как CI устроен
- Интеграция с VCS
- CI в тестировании
- Итого
Что такое CI
CI — это сборка, деплой и тестирование приложения без участия человека. Сейчас объясню на примере.
Допустим, что у нас есть два разработчика — Маша и Ваня. И тестировщица Катя.
Маша пишет код. Добавляет его в систему контроля версий (от англ. Version Control System, VCS). Это что-то типа дропбокса для кода — место хранения, где сохраняются все изменения и в любой момент можно посмотреть кто, что и когда изменял.
Потом Ваня заканчивает свой кусок функционала. И тоже сохраняет код в VCS.
Но это просто исходный код — набор файликов с расширением . java, или любым другим. Чтобы Катя могла протестировать изменения, нужно:
java, или любым другим. Чтобы Катя могла протестировать изменения, нужно:
- Собрать билд из исходного кода
- Запустить его на тестовой машине
Сборка билда — это когда мы из набора файликов исходного кода создаем один запускаемый файл:
Собрать билд можно вручную, но это лишний геморрой: нужно помнить, что в каком порядке запустить, какие файлики зависят друг от друга, не ошибиться в команде… Обычно используют специальную программу. Для java это Ant, Maven или Gradle. С помощью сборщика вы один раз настраиваете процесс сборки, а потом запускаете одной командой. Пример запуска для Maven:
mvn clean install
Это полуавтоматизация — все равно нужен человек, который введет команду и соберет билд «ручками». Допустим, этим занимаются разработчики. Когда Катя просит билд на тестирование, Ваня обновляет версию из репозитория и собирает билд.
Но собрать билд ≠ получить приложение для тестирования. Его еще надо запустить! Этим занимается сервер приложения. Серверы бывают разные: wildfly, apache, jetty…
Его еще надо запустить! Этим занимается сервер приложения. Серверы бывают разные: wildfly, apache, jetty…
Если это wildfly, то нужно:
- Подложить билд в директорию standalone/deployments
- Запустить сервер (предварительно один раз настроив службу)
И это снова полуавтоматизация. Потому что разработчику нужно скопировать получившийся после сборки архив на тестовый стенд и включить службу. Да, это делается парой команд, но все равно человеком.
А вот если убрать из этой схемы человека — мы получим CI!
CI — это приложение, которое позволяет автоматизировать весь процесс. Оно забирает изменения из репозитория с кодом. Само! Тут есть два варианта настройки:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.
- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)
Когда CI получило изменения, оно запускает сборку билда и автотесты.
Если сборка провалилась (тесты упали, или не получилось собрать проект), система пишет электронное письмо всем заинтересованным лицам:
- Менеджеру проекта (чтобы знал, что делается!)
- Разработчику, который внес изменения
- Любому другому — как настроите, так и будет.
Если сборка прошла успешно, CI разворачивает приложение на тестовой машине. И в итоге Катька может тестировать новую сборку!
Да, разумеется, один раз придется это все настроить — рассказать серверу CI, откуда забирать изменения, какие автотесты запускать, как собирать проект, куда его потом билдить… Но зато один раз настроил — а дальше оно само!
Автотесты тоже придется писать самим, но чтож поделать =)
Если на пальцах, то система CI (Continuous Integration) – это некая программа, которая следит за вашим Source Control, и при появлении там изменений автоматически стягивает их, билдит, гоняет автотесты (конечно, если их пишут).
В случае неудачи она дает об этом знать всем заинтересованным лицам, в первую очередь – последнему коммитеру. (с) habr.com/ru/post/352282
Программы CI
Наиболее популярные — Jenkins и TeamCity.
Но есть куча других вариаций — CruiseControl, CruiseControl.Net, Atlassian Bamboo, Hudson, Microsoft Team Foundation Server.
Как это выглядит
Давайте посмотрим, как это выглядит с точки зрения пользователя. Я покажу на примере системы TeamCity.
Когда я захожу в систему, я вижу все задачи. Задачи бывают разные:
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
Задачи можно группировать. Вот, скажем, у нас есть проект CDI. Зайдя внутрь, я вижу задачи именно по этому проекту:
Зайдя внутрь, я вижу задачи именно по этому проекту:
- CDI Archetype и CDI Core — это билды. Они проверяют, что приложение вообще собирается. Отрабатывают за пару минут и прогоняются на каждое изменение кода.
- CDI Core with tests — сборка проекта со всеми автотестами, которых, как видно на скрине, 4000+ штук. Тесты идут полчаса, но тоже прогоняются на каждый коммит.
Помимо автоматизированного запуска, я могу в любой момент пересобрать билд, нажав на кнопку «Run»:
Это нужно, чтобы:
- Перезапустить тесты, исправив косяк — это ведь может быть настройки окружения, а не кода. Поэтому исправление настройки не перезапустит тесты, которые следят только за системой контроля версий кода.
- Перезапустить билд, если TeamCIty настроен проверять изменения раз в час — а нам нужно сейчас проверить исправления
- Перезапустить билд, если в VCS исправления вносились не в этот проект, а в связанный.

- Проверить стабильность падения — иногда тесты падают по неведомым причинам, а если их перезапустить, отработают успешно.
Когда я захожу внутрь любой задачи — я вижу историю сборок. Когда она запускалась? Кто при этом вносил изменения и сколько их было? Сколько тестов прошло успешно, а сколько развалилось?
Поэтому, даже если я не подписана на оповещения на электронную почту о состоянии сборок, я легко могу посмотреть, в каком состоянии сейчас система. Открываешь графический интерфейс программы и смотришь.
Как CI устроен
Как и где CI собирает билд и прогоняет автотесты? Я расскажу на примере TeamCity, но другие системы работают примерно также.
Сам TeamCity ничего не собирает. Сборка и прогон автотестов проходят на других машинах, которые называются «агенты»:
«Агент» — это простой компьютер. Железка или виртуальная машина, не суть. Но как этот комьютер понимает, что ему надо сделать?
В TeamCity есть сервер и клиент. Сервер — это то самое приложение, в котором вы потом будете тыкать кнопочки и смотреть красивую картинку «насколько все прошло успешно». Он устанавливается на одну машину.
Сервер — это то самое приложение, в котором вы потом будете тыкать кнопочки и смотреть красивую картинку «насколько все прошло успешно». Он устанавливается на одну машину.
А приложение-«клиент» устанавливается на машинах-«агентах». И когда мы нажимаем кнопку «Run» на сервере:
Сервер выбирает свободного клиента и передает ему все инструкции: что именно надо сделать. Клиент собирает билд, выполняет автотесты, собирает результат и возвращает серверу: «На, держи, отрисовывай».
Сервер отображает пользователю результат плюс рассылает email всем заинтересованным лицам.
При этом мы всегда видим, на каком конкретно агенте проходила сборка:
И можно самому выбирать, где прогонять автотесты. Потому что бывает, что автотесты падают только на одном билд-агенте. Это значит, что у него что-то не так с конфигурацией.
Допустим, исходно у нас был только один билд-агент — Buran. Название может быть абсолютно любым, его придумывает администратор, когда подключает новую машину к TeamCity как билд-агента.
Мы собирали на нем проект, проводили автотесты — все работало. А потом закупили вторую машинку и назвали Apollo. Вроде настроили также, как Буран, даже операционную систему одинаковую поставили — CentOs 7.
Но запускаем сборку на Apollo — падает. Причем падает странно, не хватает памяти или еще чего-то. Перезапускаем на Apollo — снова падает. Запускаем на Буране — проходит успешно!
Начинаем разбираться и выясняем, что в Apollo забыли про какую-то настройку. Например, не увеличили количество открытых файловых дескриптеров. Исправили, прогнали сборку на Apollo — да, работает, ура!
Мы также можем для каждой сборки настроить список агентов, на которых она может выполняться. Зачем? Например, у нас на половине агентов линукс, а на половине винда. А сборку мы только под одну систему сделали. Или на винде вылезает какой-то плавающий баг, но исправлять его долго и дорого, а все клиенты на линуксе — ну и зачем тогда?
А еще бывает, что агентов делят между проектами, чтобы не было драки — этот проект использует Бурана и Аполло, а тот Чип и Дейла. Фишка ведь в том, что на одном агенте может выполняться только одно задание. Поэтому нет смысла покупать под агент крутую тачку, сразу кучу тестов там все равно не прогнать.
Фишка ведь в том, что на одном агенте может выполняться только одно задание. Поэтому нет смысла покупать под агент крутую тачку, сразу кучу тестов там все равно не прогнать.
В итоге как это работает: сначала админ закупает компьютеры под «агенты» и устанавливает на них клиентское приложение TeamCity. Слишком крутыми они быть не должны, потому что много задач сразу делать не будут.
При этом TeamCity вы платите за количество лицензий на билд-агентов. Так что чем меньше их будет, тем лучше.
На отдельной машине админ устанавливает сервер TeamCity. И конфигурирует его — настраивает сборки, указывает, какие сборки на каких машинах можно гонять, итд. На сервере нужно место для хранения артефактов — результатов выполнения сборки.
У нас есть два проекта — Единый клиент и Фактор, которые взаимодействуют между собой. Тестировщик Единого клиента может не собирать Фактор локально. Он запускает сборку в TeamCity и скачивает готовый билд из артефактов!
Дальше уже разработчик выбирает, какую сборку он хочет запустить и нажимает «Run». Что в этот момент происходит:
Что в этот момент происходит:
1. Сервер TeamCity проверяет по списку, на каких агентах эту сборку можно запускать. Потом он проверяет, кто из этих агентов в данный момент свободен:
Нашел свободного? Отдал ему задачку!
Если все агенты заняты, задача попадает в очередь. Очередь работает по принципу FIFO — first in, first out. Кто первый встал — того и тапки.
Очередь можно корректировать вручную. Так, если я вижу, что очередь забита сборками, которые запустила система контроля версий, я подниму свою на самый верх. Если я вижу, что сборки запускали люди — значит, они тоже важные, придется подождать.
Это нормальная практика, если мощностей агентов не хватает на всей и создается очередь. Смотришь, кто ее запустил:
- Робот? Значит, это просто плановая проверка, что ничего лишнего не разломалось. Такая может и подождать 5-10-30 минут, ничего страшного
- Коллега? Ему эта сборка важна, раз не стал ждать планового запуска.
 Встаем в очередь, лезть вперед не стоит.
Встаем в очередь, лезть вперед не стоит.
Иногда можно даже отменить сборку от системы контроля версий, если уж очень припекло, а все агенты занятами часовыми тестами. В таком случае можно:
- поднять свою очередь на самый верх, чтобы она запустилась на первом же освободившемся агенте
- зайти на агент, отменить текущую сборку
- перезапустить ее! Хоть она и попадет в самый низ очереди, но просто отменять сборку некрасиво
2. Агент выполняет задачу и возвращает серверу результат
3. Сервер отрисовывает результат в графическом интерфейсе и сохраняет артефакты. Так я могу зайти в TeamCity и посмотреть в артефактах полные логи прошедших автотестов, или скачать сборку проекта, чтобы развернуть ее локально.
Настоятельно рекомендуется настроить заранее количество сборок, которые CI будет хранить. Потому что если в артефактах лежат билды по 200+ мб и их будет много, то очередной запуск сборки упадет с ошибкой «кончилось место на диске»:
4. Сервер делает рассылку по email — тут уж как настроите. Он может и позитивную рассылку делать «сборка собралась успешно», а может присылать почту только в случае неудачи «Ой-ей-ей, что-то пошло не так!».
Сервер делает рассылку по email — тут уж как настроите. Он может и позитивную рассылку делать «сборка собралась успешно», а может присылать почту только в случае неудачи «Ой-ей-ей, что-то пошло не так!».
Интеграция с VCS
Я говорила о разных вариантах настройки интеграции CI — VCS:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.
- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)
Но когда какой используется?
Лучше всего, конечно, чтобы система контроля версий оповещала сервер CI. И запускать весь цикл на каждое изменение: собрать, протестировать, задеплоить. Тогда любое изменение кода сразу попадет на тестовое окружение, которое будет максимально актуальным.
Плюс каждое изменение прогоняет автотесты. И если тесты упадут, сразу ясно, чей коммит их сломал. Ведь раньше работало и после Васиных правок вдруг сломалось — значит, это его коммит привел к падению. За редким исключением, когда падение плавающее.
Ведь раньше работало и после Васиных правок вдруг сломалось — значит, это его коммит привел к падению. За редким исключением, когда падение плавающее.
Но в реальной жизни такая схема редко применима. Только подумайте — у вас ведь может быть много проектов, много разработчиков. Каждый что-то коммитит ну хотя бы раз в полчаса. И если на каждый коммит запускать 10 сборок по полчаса — очереди в TeamCity никогда не разгребутся!
У нас у одного из продуктов есть core-модуль, а есть 15+ Заказчиков. В каждом свои автотесты. Сборка заказчика — это core + особенности заказчика. То есть изменение в корневом проекте может повлиять на 15 разных сборок. Значит, их все надо запустить при коммите в core.Когда у нас было 4 билд-агента, все-все-все сборки и тесты по этим заказчикам запускались в ночь на вторник. И к 10 утра в TeamCity еще была очередь на пару часов.
Другой вариант — закупить много агентов. Но это цена за саму машину + за лицензию в TeamCity, что уже сильно дороже, да еще и каждый месяц платить.
Поэтому обычно делают как:
1. Очень быстрые и важные сборки можно оставить на любой коммит — если это займет 1-2 минуты, пусть гоняется.
2. Остальные сборки проверяют, были ли изменения в VCS — например, раз в 15 минут. Если были, тогда запускаем.
3. Долгие тесты (например, тесты производительности) — раз в несколько дней ночью.
CI в тестировании
Если мы говорим о разработке своего приложения, то тестирование входит в стандартный цикл. Вы или ваши разработчики пишут автотесты, которые потом гоняет CI. Это могут быть unit, api, gui или нагрузочные тесты.
Но что, если вы тестируете черный ящик? Приложение есть, исходного кода нету. Это суровые реалии тестировщиков интеграции — поставщик отдает вам новый релиз приложения, который нужно проверить перед тем, как ставить в продакшен.
Вот, допустим, у вас есть API-тесты в Postman-е. Или GUI-тесты в Selenium. Можно ли настроить цикл CI для них?
Конечно, можно!
CI не ставит жестких рамок типа «я работаю только в проектах с автотестами» или «я работаю только когда есть доступ к исходному коду». Он может смотреть в систему контроля версий, а может и не смотреть. Это необязательное условие!
Он может смотреть в систему контроля версий, а может и не смотреть. Это необязательное условие!
Написали автотесты? Скажите серверу CI, как часто их запускать — и наслаждайтесь результатом =)
Итого
CI — непрерывная интеграция. Это когда ваше приложение постоянно проверяется: все ли с ним хорошо? Проходят ли тесты? Собирается ли сборка? Причем все проверки проводятся автоматически, без участия человека.
Особенно актуально для команд, где над кодом одного приложения трудятся несколько разработчиков. Как это бывает? По отдельности части программы работают, а вот вместе уже нет. CI позволяет очень быстро обнаружить такие проблемы. А чем быстрее найдешь — тем дешевле исправить.
Отсюда и название — постоянная проверка интеграции кусочков кода между собой.
Типичные задачи CI:
- Проверить, было ли обновление в коде
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
И все это — автоматически, без вмешательства человека! То есть один раз настроили, а дальше оно само.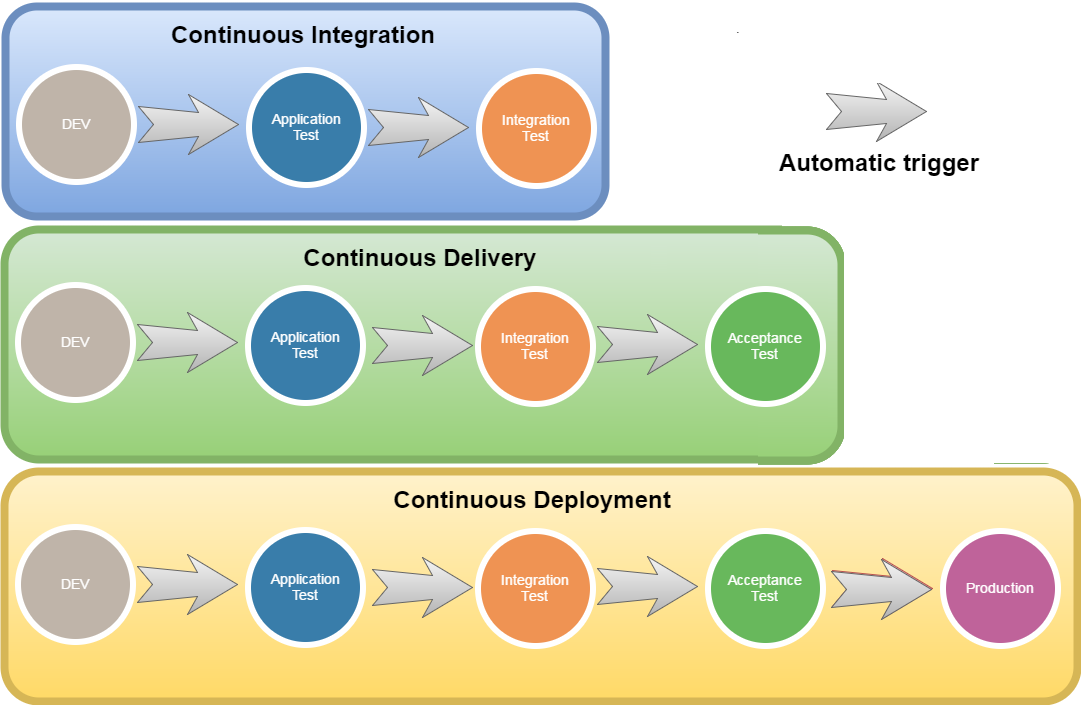
Если в проекте настроен CI, у вас будут постоянно актуальные тестовые стенды. И если в коде что-то сломается, вы узнаете об этом сразу, сервер CI пришлет письмо. А еще можно зайти в графический интерфейс и посмотреть — все ли сборки успешные, а тесты зеленые? Оценить картину по проекту за минуту.
См также:
Continuous Integration для новичков
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Что такое непрерывная интеграция | Atlassian
Повысьте гибкость своей команды с помощью более быстрой обратной связи. Потому что вы двигаетесь так же быстро, как и ваши тесты.
Непрерывная интеграция (CI) — это практика автоматизации интеграции изменений кода от нескольких участников в единый программный проект. Это основная передовая практика DevOps, позволяющая разработчикам часто объединять изменения кода в центральный репозиторий, где затем выполняются сборки и тесты. Автоматизированные инструменты используются для проверки правильности нового кода перед интеграцией.
Система управления версиями исходного кода является основой процесса CI. Система контроля версий также дополнена другими проверками, такими как автоматические тесты качества кода, инструменты проверки стиля синтаксиса и многое другое.
Пять советов по репозиториям Git, оптимизированным для CI
Пять советов, как максимально эффективно использовать Git и ваш инструмент непрерывной интеграции! Прочтите статью
Инструменты непрерывной интеграции
Пять советов, как максимально эффективно использовать Git и ваш инструмент непрерывной интеграции! Читать статью
Разработка на основе магистрали
Узнайте о разработке на основе магистрали, практике управления версиями, при которой разработчики объединяют небольшие частые обновления в основную «магистраль» или основную ветвь. Прочтите статью
Руководство по непрерывной интеграции
В этом руководстве показано, как начать работу с непрерывной интеграцией, выполнив три простых шага. Попробуйте руководство
Попробуйте руководство
Важность непрерывной интеграции
Чтобы понять важность CI, полезно сначала обсудить некоторые болевые точки, которые часто возникают из-за отсутствия CI. Без CI разработчики должны вручную координировать и сообщать, когда они вносят свой код в конечный продукт. Эта координация распространяется не только на команды разработчиков, но и на операции и остальную часть организации. Продуктовые группы должны координировать, когда последовательно запускать функции и исправления, а также какие члены команды будут нести за это ответственность.
Накладные расходы на связь в среде без CI могут превратиться в сложную и запутанную рутинную синхронизацию, которая увеличивает ненужные бюрократические затраты на проекты. Это приводит к более медленным выпускам кода с более высоким уровнем отказов, поскольку требует от разработчиков деликатности и внимательности к интеграции. Эти риски растут в геометрической прогрессии по мере увеличения размеров команды разработчиков и кодовой базы.
Без надежного конвейера непрерывной интеграции может возникнуть разрыв между инженерной командой и остальной частью организации. Связь между продуктом и инженерами может быть сложной. Инженерия становится черным ящиком, в который остальная часть команды вводит требования и функции и, возможно, получает ожидаемые результаты. Инженерам будет сложнее оценивать время доставки по запросам, потому что время для интеграции новых изменений становится неизвестным риском.
Чем занимается CI
CI помогает увеличить численность персонала и производительность инженерных групп. Внедрение CI в вышеупомянутый сценарий позволяет разработчикам программного обеспечения параллельно работать над функциями независимо друг от друга. Когда они будут готовы объединить эти функции в конечный продукт, они смогут сделать это независимо и быстро. CI — ценная и хорошо зарекомендовавшая себя практика в современных высокопроизводительных организациях по разработке программного обеспечения.
Как можно использовать CI
CI обычно используется вместе с гибким рабочим процессом разработки программного обеспечения. Организация составит список задач, составляющих дорожную карту продукта. Затем эти задачи распределяются между членами группы разработки программного обеспечения для выполнения. Использование CI позволяет разрабатывать эти задачи разработки программного обеспечения независимо и параллельно между назначенными разработчиками. Как только одна из этих задач будет выполнена, разработчик введет эту новую работу в систему CI, чтобы интегрировать ее с остальной частью проекта.
CI, непрерывное развертывание и непрерывная доставка
Непрерывная интеграция, развертывание и доставка — это три этапа автоматизированного конвейера выпуска программного обеспечения, включая конвейер DevOps. Эти три этапа ведут программное обеспечение от идеи до доставки конечному пользователю. Этап интеграции — это первый шаг в этом процессе. Непрерывная интеграция охватывает процесс, когда несколько разработчиков пытаются объединить свои изменения кода с основным хранилищем кода проекта.
Непрерывная поставка — это следующее расширение непрерывной интеграции. Этап доставки отвечает за упаковку артефакта для доставки конечным пользователям. На этом этапе запускаются инструменты автоматизированного построения для создания этого артефакта. Эта фаза сборки остается «зеленой», что означает, что артефакт должен быть готов к развертыванию для пользователей в любой момент времени.
Непрерывное развертывание — это заключительный этап конвейера. Этап развертывания отвечает за автоматический запуск и распространение программного артефакта среди конечных пользователей. Во время развертывания артефакт успешно прошел этапы интеграции и доставки. Теперь пришло время автоматически развернуть или распространить артефакт. Это будет происходить с помощью сценариев или инструментов, которые автоматически перемещают артефакт на общедоступные серверы или в другой механизм распространения, например в магазин приложений.
Преимущества и проблемы непрерывной интеграции
Непрерывная интеграция — важный аспект DevOps и высокопроизводительных групп разработчиков программного обеспечения. Тем не менее, преимущества CI не ограничиваются командой инженеров, а приносят большую пользу организации в целом. Конвергентная инфраструктура обеспечивает большую прозрачность и понимание процесса разработки и доставки программного обеспечения. Эти преимущества позволяют остальной части организации лучше планировать и реализовывать стратегии выхода на рынок. Ниже приведены некоторые общие организационные преимущества CI.
Тем не менее, преимущества CI не ограничиваются командой инженеров, а приносят большую пользу организации в целом. Конвергентная инфраструктура обеспечивает большую прозрачность и понимание процесса разработки и доставки программного обеспечения. Эти преимущества позволяют остальной части организации лучше планировать и реализовывать стратегии выхода на рынок. Ниже приведены некоторые общие организационные преимущества CI.
Включить масштабирование
Конвергентная инфраструктура позволяет организациям масштабировать размер группы инженеров, размер кодовой базы и инфраструктуру. Сводя к минимуму бюрократию интеграции кода и накладные расходы на связь, CI помогает создавать DevOps и гибкие рабочие процессы. Это позволяет каждому члену команды владеть новым изменением кода до выпуска. CI обеспечивает масштабирование, устраняя любые организационные зависимости между разработкой отдельных функций. Теперь разработчики могут работать над функциями изолированно и быть уверенными, что их код будет беспрепятственно интегрироваться с остальной кодовой базой, что является основным процессом DevOps.
Улучшение цикла обратной связи
Более быстрая обратная связь по бизнес-решениям — еще один мощный побочный эффект CI. С помощью оптимизированной платформы CI команды разработчиков продуктов могут быстрее тестировать идеи и разрабатывать проекты продуктов. Изменения можно быстро внедрить и оценить их успех. Ошибки или другие проблемы могут быть быстро устранены и устранены.
Улучшение связи
Конвергентная инфраструктура улучшает общую инженерную коммуникацию и подотчетность, что обеспечивает более тесное сотрудничество между разработчиками и операциями в команде DevOps. Внедряя рабочие процессы запросов на вытягивание, привязанные к CI, разработчики получают пассивный обмен знаниями. Запросы на вытягивание позволяют разработчикам наблюдать за кодом других членов команды и комментировать его. Теперь разработчики могут просматривать и совместно работать над ветвями функций с другими разработчиками по мере того, как функции продвигаются по конвейеру CI. CI также можно использовать для уменьшения расходов на ресурсы QA. Эффективный конвейер непрерывной интеграции с высоконадежным автоматизированным тестовым покрытием защитит от регрессий и обеспечит соответствие новых функций спецификации. Прежде чем новый код будет объединен, он должен пройти набор утверждений теста CI, который предотвратит любые новые регрессии.
CI также можно использовать для уменьшения расходов на ресурсы QA. Эффективный конвейер непрерывной интеграции с высоконадежным автоматизированным тестовым покрытием защитит от регрессий и обеспечит соответствие новых функций спецификации. Прежде чем новый код будет объединен, он должен пройти набор утверждений теста CI, который предотвратит любые новые регрессии.
Преимущества CI намного перевешивают любые трудности при внедрении. Тем не менее, важно знать о проблемах CI. Настоящие проблемы CI возникают при переходе проекта от отсутствия CI к CI. Большинство современных программных проектов внедряют CI на ранних стадиях создания и облегчают проблемы последующего внедрения.
Принятие и установка
Проблемы непрерывной интеграции в первую очередь связаны с адаптацией команды и первоначальной технической установкой. Если у команды в настоящее время нет готового решения CI, может потребоваться некоторое усилие, чтобы выбрать его и приступить к работе. Таким образом, при установке конвейера CI необходимо учитывать существующую инженерную инфраструктуру.
Кривая обучения технологиям
Функциональность CI поставляется со списком вспомогательных технологий, которые могут стать инвестициями в обучение для команды. Этими технологиями являются системы контроля версий, хостинговая инфраструктура и технологии оркестровки.
Передовой опыт непрерывной интеграции
Разработка через тестирование
После того, как проект создал конвейер непрерывной интеграции с автоматическим тестовым покрытием, рекомендуется постоянно развивать и улучшать тестовое покрытие. Каждая новая функция, поступающая в конвейер CI, должна сопровождаться набором тестов, подтверждающих, что новый код ведет себя так, как ожидалось.
Разработка через тестирование (TDD) — это практика написания тестового кода и тестовых примеров перед тем, как приступить к фактическому кодированию функций. Чистый TDD может тесно вовлечь команду разработчиков, чтобы помочь разработать спецификацию ожидаемого поведения бизнеса, которая затем может быть преобразована в тестовые сценарии. В чистом сценарии TDD разработчики и команда разработчиков встречаются и обсуждают спецификацию или список требований. Затем этот список требований будет преобразован в контрольный список утверждений кода. Затем разработчики напишут код, соответствующий этим утверждениям.
В чистом сценарии TDD разработчики и команда разработчиков встречаются и обсуждают спецификацию или список требований. Затем этот список требований будет преобразован в контрольный список утверждений кода. Затем разработчики напишут код, соответствующий этим утверждениям.
Запросы на вытягивание и проверка кода
Большинство современных групп разработчиков программного обеспечения практикуют рабочий процесс запросов на вытягивание и проверки кода. Запросы на вытягивание — важная практика для эффективной CI. Запрос на вытягивание создается, когда разработчик готов объединить новый код с основной кодовой базой. Запрос на вытягивание уведомляет других разработчиков о новом наборе изменений, которые готовы к интеграции.
Запросы на вытягивание — подходящее время для запуска конвейера непрерывной интеграции и выполнения набора автоматических шагов утверждения. Дополнительный этап утверждения вручную обычно добавляется во время запроса на вытягивание, во время которого инженер, не являющийся заинтересованным лицом, выполняет проверку кода функции. Это позволяет свежим взглядом просмотреть новый код и функциональность. Сторонний пользователь внесет предложения по редактированию и одобрит или отклонит запрос на вытягивание.
Это позволяет свежим взглядом просмотреть новый код и функциональность. Сторонний пользователь внесет предложения по редактированию и одобрит или отклонит запрос на вытягивание.
Запросы на вытягивание и проверка кода — это мощный инструмент для пассивного общения и обмена знаниями между командой разработчиков. Это помогает защититься от технического долга в виде хранилищ знаний, когда конкретные инженеры являются единственными заинтересованными сторонами для определенных функций базы кода.
Оптимизация скорости конвейера
Учитывая, что конвейер CI будет центральным и часто используемым процессом, важно оптимизировать скорость его выполнения. Любая небольшая задержка в рабочем процессе CI будет увеличиваться в геометрической прогрессии по мере роста количества выпусков функций, размера команды и размера кодовой базы. Рекомендуется измерять скорость конвейера CI и при необходимости оптимизировать.
Более быстрый конвейер CI обеспечивает более быстрый цикл обратной связи о продукте. Разработчики могут быстро вносить изменения и экспериментировать с идеями новых функций, чтобы улучшить взаимодействие с пользователем. Любые исправления ошибок могут быть быстро исправлены и устранены по мере обнаружения. Эта повышенная скорость выполнения может дать вашим клиентам как преимущество перед другими конкурентами, так и общее более высокое качество обслуживания.
Разработчики могут быстро вносить изменения и экспериментировать с идеями новых функций, чтобы улучшить взаимодействие с пользователем. Любые исправления ошибок могут быть быстро исправлены и устранены по мере обнаружения. Эта повышенная скорость выполнения может дать вашим клиентам как преимущество перед другими конкурентами, так и общее более высокое качество обслуживания.
Начало работы с непрерывной интеграцией
Основополагающей зависимостью CI является система контроля версий (VCS). Если целевая кодовая база для установки CI не имеет VCS, первым шагом является установка VCS. Отсутствие VCS должно быть очень маловероятным в современных кодовых базах. Некоторые популярные VCS — это Git, Mercurial и Subversion.
После того, как система управления версиями установлена, следующим шагом будет поиск платформы для размещения системы контроля версий. Большинство современных инструментов хостинга с контролем версий имеют встроенную поддержку и функции для CI. Некоторыми популярными платформами хостинга с контролем версий являются Bitbucket, Github и Gitlab.
Некоторыми популярными платформами хостинга с контролем версий являются Bitbucket, Github и Gitlab.
После того, как в проекте установлен контроль версий, необходимо добавить этапы утверждения интеграции. Наиболее важным этапом утверждения интеграции являются автоматические тесты. Добавление автоматических тестов в проект может иметь первоначальные накладные расходы. Должна быть установлена среда тестирования, затем разработчики должны написать тестовый код и тестовые примеры.
Некоторые идеи для добавления других, менее дорогих механизмов утверждения CI включают средства проверки синтаксиса, средства форматирования стиля кода или сканирование уязвимостей зависимостей. После того, как вы настроили систему контроля версий с некоторыми шагами утверждения слияния, вы установили непрерывную интеграцию!
Конвергентная интеграция — это не только бизнес-процесс, специфичный для инженеров. Остальные отделы организации, маркетинга, продаж и продуктов также выиграют от конвейера непрерывной интеграции. Продуктовым группам нужно будет подумать, как распараллелить выполнение одновременных потоков разработки. Продукт и инженеры будут тесно сотрудничать, чтобы определить соответствующие бизнес-функциональные возможности, которые составят набор автоматизированных тестов.
Продуктовым группам нужно будет подумать, как распараллелить выполнение одновременных потоков разработки. Продукт и инженеры будут тесно сотрудничать, чтобы определить соответствующие бизнес-функциональные возможности, которые составят набор автоматизированных тестов.
Маркетинг и отдел продаж смогут ссылаться на конвейер CI для координации усилий и мероприятий по коммуникации с клиентами. Конвергентная инфраструктура обеспечивает уровень прозрачности для остальной части организации в отношении того, как продвигается инженерное исполнение. Эта утилита прозрачности и коммуникации изящно интегрируется с гибким рабочим процессом разработки проекта.
В заключение…
Если ваша организация стремится воспользоваться преимуществами подхода DevOps или просто имеет команду разработчиков программного обеспечения, состоящую из нескольких разработчиков, CI важна. Это поможет вашей инженерной организации работать быстрее и эффективнее.
Конвергентная инфраструктура — стандартная составляющая современных высокоэффективных организаций по разработке программного обеспечения. Лучшие компании имеют надежные конвейеры непрерывной интеграции и не задумываются о дальнейших инвестициях в повышение эффективности. Преимущества CI не ограничиваются командой инженеров и применимы ко всей организации.
Лучшие компании имеют надежные конвейеры непрерывной интеграции и не задумываются о дальнейших инвестициях в повышение эффективности. Преимущества CI не ограничиваются командой инженеров и применимы ко всей организации.
Существует множество сторонних инструментов, помогающих в управлении и установке CI. Некоторые популярные варианты: Codeship, Bitbucket Pipelines, SemaphoreCI, CircleCI, Jenkins, Bamboo, Teamcity и многие другие. Эти инструменты имеют собственные подробные руководства по настройке и документацию, которые помогут начать работу.
Попробуйте некоторые из лучших инструментов непрерывной интеграции, предоставляемых Atlassian:
Конвейеры Bitbucket — отличная утилита для ускорения проекта с использованием современных функций непрерывной интеграции.
Jira — один из самых популярных в мире инструментов управления проектами Agile и DevOps. Он тесно интегрируется с другими проектами Bitbucket и в сочетании с конвейером непрерывной интеграции может дать очень прозрачное представление о работоспособности организации.
Попробуйте Bitbucket Pipelines сейчас
Попробуйте Jira сейчас
Макс Рекопф
Как самопровозглашенная «кукла хаоса» я обращаюсь к agile-практикам и принципам бережливого производства, чтобы навести порядок в своей повседневной жизни. Мне очень приятно делиться этими уроками с другими через множество статей, выступлений и видео, которые я делаю для Atlassian
Следующая тема
Рекомендуемое чтение
Добавьте эти ресурсы в закладки, чтобы узнать о типах команд DevOps или для текущих новости о DevOps в Atlassian.
Сообщество DevOps
Прочтите блог
Начало работы бесплатно
Зарегистрируйтесь в нашей рассылке DevOps
Адрес электронной почты
Благодарность за подпись
Непревзой. Узнайте о различиях между этими непрерывными практиками
Sten Pettet
Contributing Writer
CI и CD — это две аббревиатуры, которые часто используются в современных методах разработки и DevOps. CI означает непрерывную интеграцию, фундаментальную передовую практику DevOps, когда разработчики часто объединяют изменения кода в центральный репозиторий, где выполняются автоматизированные сборки и тесты. Но CD может означать либо непрерывную доставку, либо непрерывное развертывание.
CI означает непрерывную интеграцию, фундаментальную передовую практику DevOps, когда разработчики часто объединяют изменения кода в центральный репозиторий, где выполняются автоматизированные сборки и тесты. Но CD может означать либо непрерывную доставку, либо непрерывное развертывание.
Непрерывная интеграция
Разработчики, практикующие непрерывную интеграцию, как можно чаще сливают свои изменения обратно в основную ветку. Изменения, внесенные разработчиком, проверяются путем создания сборки и выполнения автоматических тестов для сборки. Поступая так, вы избегаете проблем с интеграцией, которые могут возникнуть при ожидании дня выпуска для объединения изменений в ветку выпуска.
Непрерывная интеграция уделяет большое внимание автоматизации тестирования, чтобы убедиться, что приложение не нарушается всякий раз, когда новые коммиты интегрируются в основную ветвь.
Непрерывная доставка
Непрерывная доставка — это расширение непрерывной интеграции, поскольку она автоматически развертывает все изменения кода в тестовой и/или производственной среде после этапа сборки.
Это означает, что помимо автоматического тестирования у вас есть автоматизированный процесс выпуска, и вы можете развернуть свое приложение в любое время, нажав кнопку.
Теоретически при непрерывной доставке вы можете выпускать ежедневно, еженедельно, раз в две недели или в зависимости от требований вашего бизнеса. Однако, если вы действительно хотите воспользоваться преимуществами непрерывной доставки, развертывание в рабочей среде следует выполнять как можно раньше, чтобы убедиться, что вы выпускаете небольшие партии, которые легко устранить в случае возникновения проблемы.
См. решение
Создание и использование программного обеспечения с помощью Open DevOps
Связанный материал
Что такое конвейер DevOps?
Непрерывное развертывание
Непрерывное развертывание — это еще один шаг вперед по сравнению с непрерывной доставкой. Благодаря этой практике каждое изменение, прошедшее все этапы производственного конвейера, передается вашим клиентам. Вмешательства человека нет, и только неудачный тест предотвратит развертывание нового изменения в рабочей среде.
Вмешательства человека нет, и только неудачный тест предотвратит развертывание нового изменения в рабочей среде.
Непрерывное развертывание — отличный способ ускорить цикл обратной связи с вашими клиентами и снять нагрузку с команды, поскольку «дня релиза» больше нет. Разработчики могут сосредоточиться на создании программного обеспечения, и они видят, как их работа начинает работать через несколько минут после того, как они закончили работу над ней.
Как практики соотносятся друг с другом
Проще говоря, непрерывная интеграция является частью как непрерывной доставки, так и непрерывного развертывания. И непрерывное развертывание похоже на непрерывную доставку, за исключением того, что выпуски происходят автоматически.
Каковы преимущества каждой практики?
Мы объяснили разницу между непрерывной интеграцией, непрерывной доставкой и непрерывным развертыванием, но еще не рассмотрели причины, по которым вы должны их принять. Внедрение каждой практики сопряжено с очевидными затратами, но их преимущества в значительной степени перевешивают их.
Непрерывная интеграция
Что вам нужно (стоимость)
- Ваша команда должна будет написать автоматизированные тесты для каждой новой функции, улучшения или исправления ошибки.
- Вам нужен сервер непрерывной интеграции, который может отслеживать основной репозиторий и автоматически запускать тесты для каждой новой фиксации.
- Разработчики должны объединять свои изменения как можно чаще, по крайней мере, один раз в день.
Что вы получаете
- В рабочую среду отправляется меньше ошибок, поскольку автоматические тесты фиксируют регрессии на ранней стадии.
- Создать выпуск легко, так как все проблемы с интеграцией были решены заранее.
- Меньше переключений контекста, поскольку разработчики получают оповещения, как только они нарушают сборку, и могут работать над ее исправлением, прежде чем перейти к другой задаче.
- Затраты на тестирование резко сокращаются — ваш CI-сервер может выполнять сотни тестов за считанные секунды.

- Ваша группа обеспечения качества тратит меньше времени на тестирование и может сосредоточиться на значительных улучшениях культуры качества.
Непрерывная поставка
Что вам нужно (стоимость)
- Вам нужна прочная основа для непрерывной интеграции, и ваш набор тестов должен охватывать достаточное количество кода.
- Необходимо автоматизировать развертывание. Триггер по-прежнему запускается вручную, но после запуска развертывания не должно быть необходимости во вмешательстве человека.
- Скорее всего, вашей команде потребуется использовать флаги функций, чтобы незавершенные функции не влияли на клиентов в рабочей среде.
Что вы получаете
- Сложность развертывания программного обеспечения устранена. Вашей команде больше не нужно тратить дни на подготовку к релизу.
- Вы можете выпускать обновления чаще, тем самым ускоряя обратную связь с вашими клиентами.
- При принятии решений о небольших изменениях гораздо меньше давления, что способствует более быстрому повторению.

Непрерывное развертывание
Что вам нужно (стоимость)
- Ваша культура тестирования должна быть на высоте. Качество вашего набора тестов будет определять качество ваших релизов.
- Процесс документации должен соответствовать темпам развертывания.
- Флажки функций становятся неотъемлемой частью процесса выпуска значительных изменений, чтобы обеспечить возможность координации с другими отделами (поддержка, маркетинг, PR…).
Что вы получите
- Вы сможете разрабатывать быстрее, так как нет необходимости приостанавливать разработку для выпусков. Конвейеры развертывания запускаются автоматически при каждом изменении.
- Релизы менее рискованны и их легче исправить в случае возникновения проблемы при развертывании небольших пакетов изменений.
- Клиенты видят непрерывный поток улучшений и повышение качества каждый день, а не каждый месяц, квартал или год.
Одной из традиционных статей затрат, связанных с непрерывной интеграцией, является установка и обслуживание сервера CI. Но вы можете значительно снизить затраты на внедрение этих методов, используя облачный сервис, такой как Bitbucket Pipelines, который добавляет автоматизацию в каждый репозиторий Bitbucket. Просто добавив файл конфигурации в корень вашего репозитория, вы сможете создать конвейер непрерывного развертывания, который будет выполняться для каждого нового изменения, отправленного в основную ветку.
Но вы можете значительно снизить затраты на внедрение этих методов, используя облачный сервис, такой как Bitbucket Pipelines, который добавляет автоматизацию в каждый репозиторий Bitbucket. Просто добавив файл конфигурации в корень вашего репозитория, вы сможете создать конвейер непрерывного развертывания, который будет выполняться для каждого нового изменения, отправленного в основную ветку.
Переход от непрерывной интеграции к непрерывному развертыванию
Если вы только начинаете новый проект без пользователей, вам может быть легко развертывать каждую фиксацию в рабочей среде. Вы даже можете начать с автоматизации развертывания и выпуска альфа-версии в производство без клиентов. Затем вы можете повысить свою культуру тестирования и убедиться, что вы увеличиваете охват кода при создании приложения. К тому времени, когда вы будете готовы к подключению пользователей, у вас будет отличный непрерывный процесс развертывания, в котором все новые изменения тестируются перед автоматическим выпуском в рабочую среду.
Но если у вас уже есть существующее приложение с клиентами, вам следует замедлить процесс и начать с непрерывной интеграции и непрерывной доставки. Начните с реализации базовых модульных тестов, которые выполняются автоматически — пока нет необходимости сосредотачиваться на выполнении сложных сквозных тестов. Вместо этого вам следует как можно скорее попытаться автоматизировать свои развертывания и перейти к этапу, на котором развертывания в промежуточных средах выполняются автоматически. Причина в том, что если у вас есть автоматическое развертывание, вы можете сосредоточить свою энергию на улучшении своих тестов, а не на периодической остановке для координации выпуска.
Как только вы сможете ежедневно выпускать программное обеспечение, вы можете заняться непрерывным развертыванием. Но убедитесь, что остальная часть вашей организации также готова: документация, поддержка, маркетинг и т. д. Эти функции должны будут адаптироваться к новой частоте выпусков, и важно, чтобы они не пропускали существенные изменения, которые могут повлиять клиенты.